https://github.com/facebookresearch/llama.git 先大体看看工程结构,每个文件都是啥; 然后整体串下流程,看看chat的数据结构定义,inference整体流程 最后用例子重点看看token化细节、模型框架定义细节、模型加载细节、forward细节 并行执行框架留到下次(找几张卡演示,或找个apple版本的);训练和fine-tuning文件也留到下次
运行环境
代码默认跑在gpu上,在mac上跑要把所有用cuda的地方都改掉
模型文件
开源有6个可选 MODEL_SIZE=”7B,13B,70B,7B-chat,13B-chat,70B-chat”
以llama-2-7b-chat为例,里面三个文件:
1)checklist.chk
记录的是模型文件的MD5,内容长这样:
0c4837f3ef97f648452f91faed308a07 consolidated.00.pth
1c39bc3c6b51079fd807cc105b86c9df params.json
2)consolidated.00.pth
13G大小,这是模型的checkpoint文件。前几行长这样
consolidated/data.pklFB ZZZZZZZZZ�}q(Xtok_embeddings.weightqctorch._utils
_rebuild_tensor_v2
q((Xstorageqctorch
BFloat16Storage
qX0qXcpuqJ�tqQKM}M�MK�q �ccollections
OrderedDict
q
)Rq
tq
X R
norm.weightqh((hhX1qhMtqQKM�qK�q�h
output.weightqh((hhX2qhJ�tqQKM}M�qMK�q�h
)RqqRqXlayers.0.attention.wq.weightqh((hhX3qhJtq QKMM�q!MK�q"�h
)Rq#tq$Rq%Xlayers.0.attention.wk.weightq&h((hhX4q'hJtq(QKMM�q)MK�q*�h
)Rq+tq,Rq-Xlayers.0.attention.wv.weightq.h((hhX5q/hJtq0QKMM�q1MK�q2�h
)Rq3tq4Rq5Xlayers.0.attention.wo.weightq6h((hhX6q7hJtq8QKMM�q9MK�q:�h
)Rq;tq<Rq=Xlayers.0.feed_forward.w1.weightq>h((hhX7q?hJ�tq@QKM+M�qAMK�qB�h
)RqCtqDRqEXlayers.0.feed_forward.w2.weightqFh((hhX8qGhJ�tqHQKMM+�qIM+K�qJ�h
)RqKtqLRqMXlayers.0.feed_forward.w3.weightqNh((hhX9qOhJ�tqPQKM+M�qQMK�qR�h
)RqStqTRqUXlayers.0.attention_norm.weightqVh((hhX10qWhMtqXQKM�qYK�qZ�h
)Rq[tq\Rq]Xlayers.0.ffn_norm.weightq^h((hhX11q_hMtq`QKM�qaK�qb�h
)RqctqdRqeXlayers.1.attention.wq.weightqfh((hhX12qghJtqhQKMM�qiMK�qj�h
)RqktqlRqmXlayers.1.attention.wk.weightqnh((hhX13qohJtqpQKMM�qqMK�qr�h
)RqstqtRquXlayers.1.attention.wv.weightqvh((hhX14qwhJtqxQKMM�qyMK�qz�h
)Rq{tq|Rq}Xlayers.1.attention.wo.weightq~h((hhX15qhJtq�QKMM�q�MK�q��h
)Rq�tq�Rq�Xlayers.1.feed_forward.w1.weightq�h((hhX16q�hJ�tq�QKM+M�q�MK�q��h
)Rq�tq�Rq�Xlayers.1.feed_forward.w2.weightq�h((hhX17q�hJ�tq�QKMM+�q�M+K�q��h
)Rq�tq�Rq�Xlayers.1.feed_forward.w3.weightq�h((hhX18q�hJ�tq�QKM+M�q�MK�q��h
)Rq�tq�Rq�Xlayers.1.attention_norm.weightq�h((hhX19q�hMtq�QKM�q�K�q��h
)Rq�tq�Rq�Xlayers.1.ffn_norm.weightq�h((hhX20q�hMtq�QKM�q�K�q��h
)Rq�tq�Rq�Xlayers.2.attention.wq.weightq�h((hhX21q�hJtq�QKMM�q�MK�q��h
)Rq�tq�Rq�Xlayers.2.attention.wk.weightq�h((hhX22q�hJtq�QKMM�q�MK�q��h
)Rq�tq�Rq�Xlayers.2.attention.wv.weightq�h((hhX23q�hJtq�QKMM�q�MK�qh
)Rq�tq�Rq�Xlayers.2.attention.wo.weightq�h((hhX24q�hJtq�QKMM�q�MK�qʉh
)Rq�tq�Rq�Xlayers.2.feed_forward.w1.weightq�h((hhX25q�hJ�tq�QKM+M�q�MK�q҉h
)Rq�tq�Rq�Xlayers.2.feed_forward.w2.weightq�h((hhX26q�hJ�tq�QKMM+�q�M+K�qډh
)Rq�tq�Rq�Xlayers.2.feed_forward.w3.weightq�h((hhX27q�hJ�tq�QKM+M�q�MK�q�h
)Rq�tq�Rq�Xlayers.2.attention_norm.weightq�h((hhX28q�hMtq�QKM�q�K�q�h
)Rq�tq�Rq�Xlayers.2.ffn_norm.weightq�h((hhX29q�hMtq�QKM�q�K�q�h
3)params.json
{"dim": 4096, "multiple_of": 256, "n_heads": 32, "n_layers": 32, "norm_eps": 1e-06, "vocab_size": -1}
chat数据结构
这次例子用的数据结构如下:
[
[
{"role": "system", "content": "Always answer by Chinese"},
{"role": "user", "content": "I am going to Beijing, what should I see?"}
],
[
{"role": "system", "content": "Be cute"},
{"role": "user", "content": "What is PyTorch?"}
]
]
第一层数组对应是batch size,代表这可以有多段对话可以一起做inference计算。 在这个例子里,batch size=2。
第二层字典是每一个对话的具体内容,顺序是”system”、0-N个{“user”“assistant”}、”user” 这个结构是专门为对话场景设计的,system代表系统promot,默认的是下面这段话:
"""\
You are a helpful, respectful and honest assistant. \
Always answer as helpfully as possible, while being safe. \
Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. \
Please ensure that your responses are socially unbiased and positive in nature.\
If a question does not make any sense, or is not factually coherent,\
explain why instead of answering something not correct. \
If you don't know the answer to a question, please don't share false information."""
user代表用户的提问;assistant代表系统的回答。
生成输出的过程
先描述一下大概过程,细节在后续展开。
首先对输入内容调整格式,做token化,结果是List[List[int]]。例子的输出是2个list,长度分别为30和39。
然后调用模型,自回归生成输出。在例子中,从第31个token开始生成,一直生成到第89个token(设置了max_gen_len=50),一共自回归调用inference接口59次。
token化
复用了SentencePiece库 SentencePiece库定义了一些特殊的控制符号用于标记化和处理文本。在使用SentencePiece时,也可以自定义添加一些特殊符号,通过在训练模型时指定–user_defined_symbols参数。
<unk>: 未知标记,用于表示未在训练词汇中出现的词汇。
<s>: 开始标记,用于表示一句话或一段文本的开始。
</s>: 结束标记,用于表示一句话或一段文本的结束。
<pad>: 填充标记,用于在处理变长序列时保持输入的一致性。
<cls>, <sep>, <mask>: 这些标记在一些特定的上下文中有特别的意义,如BERT模型。其中,<cls>常用于分类任务作为全局语境的表征,<sep>用于分隔不同的句子或段落,<mask>用于遮蔽语言模型任务中的一些词汇。
但从质量看,感觉它把词切得过于碎,这三万多个token利用率不高。 llama的例子如下,像always、cute这些常用词也都切碎了,它自己定义的特殊符号«SYS»也被切成了4段。虽然这4段的固定组合能被学出来,但终归低效占用了token表意空间。
输入内容:[INST] <<SYS>>
Always answer by Chinese
<</SYS>>
I am going to Beijing, what should I see? [/INST], bos=True, eos=False
token化结果,list(分词字段,token index id): [('▁[', 518), ('INST', 25580), (']', 29962), ('▁<<', 3532), ('SY', 14816), ('S', 29903), ('>>', 6778), ('<0x0A>', 13), ('Al', 2499), ('ways', 1994), ('▁answer', 1234), ('▁by', 491), ('▁Chinese', 10013), ('<0x0A>', 13), ('<', 29966), ('</', 829), ('SY', 14816), ('S', 29903), ('>>', 6778), ('<0x0A>', 13), ('<0x0A>', 13), ('I', 29902), ('▁am', 626), ('▁going', 2675), ('▁to', 304), ('▁Be', 1522), ('ij', 823), ('ing', 292), (',', 29892), ('▁what', 825), ('▁should', 881), ('▁I', 306), ('▁see', 1074), ('?', 29973), ('▁[', 518), ('/', 29914), ('INST', 25580), (']', 29962)]
输入内容:[INST] <<SYS>>
Be cute
<</SYS>>
What is PyTorch? [/INST], bos=True, eos=False
token化结果,list(分词字段,token index id): [('▁[', 518), ('INST', 25580), (']', 29962), ('▁<<', 3532), ('SY', 14816), ('S', 29903), ('>>', 6778), ('<0x0A>', 13), ('Be', 3629), ('▁c', 274), ('ute', 1082), ('<0x0A>', 13), ('<', 29966), ('</', 829), ('SY', 14816), ('S', 29903), ('>>', 6778), ('<0x0A>', 13), ('<0x0A>', 13), ('What', 5618), ('▁is', 338), ('▁Py', 10772), ('T', 29911), ('orch', 25350), ('?', 29973), ('▁[', 518), ('/', 29914), ('INST', 25580), (']', 29962)]
相比之下,感觉bert和gpt4的token化都要比llama好。
示例:scalability的分词结果:
Ÿ gpt4 encode result: [94307, 2968] as b'scal' b'ability'
Ÿ gpt2 encode result: [1416, 282, 1799] as b'sc' b'al' b'ability'
Ÿ bert-base-uncased encode result: ['scala', '##bility']
示例:张金璐 的分词结果:
Ÿ gpt4 encode result: [87441, 35330, 163, 240, 238],内容为: 5byg 6YeR 5w== kg== kA==,反查出utf8编码为:'\xe5\xbc\xa0' '\xe9\x87\x91' '\xe7' '\x92' '\x90'。\xe5\xbc\xa0是张,\xe9\x87\x91是金,璐字不常见,并不在编码表里,处理方法是对璐字utf8编码后的三个字符分别算base64,然后取3个token。
Ÿ gpt2 encode result: [28156, 254, 34932, 239, 163, 240, 238],反查词表的结果是 "\u00e5\u00bc" "\u0142" "\u00e9\u0129" "\u0133" "\u00e7" "\u0134" '\u0132" 常用字的utf8也拆碎了表达,即占了词表空间,效果也不好。
这是例子token化后的结果,两个list,长度分别是39和30
[
[1, 518, 25580, 29962, 3532, 14816, 29903, 6778, 13, 2499, 1994, 1234, 491, 10013, 13, 29966, 829, 14816, 29903, 6778, 13, 13, 29902, 626, 2675, 304, 1522, 823, 292, 29892, 825, 881, 306, 1074, 29973, 518, 29914, 25580, 29962],
[1, 518, 25580, 29962, 3532, 14816, 29903, 6778, 13, 3629, 274, 1082, 13, 29966, 829, 14816, 29903, 6778, 13, 13, 5618, 338, 10772, 29911, 25350, 29973, 518, 29914, 25580, 29962]
]

https://drive.google.com/file/d/1NvCxje7-wtdAc5EF4X02-0q4AEruJLFn/view?usp=sharing
模型结构
不同参数量的模型,dim、layers数量等都不一样,但整体模型结构都长这样:
Transformer(
(tok_embeddings): ParallelEmbedding()
(layers): ModuleList(
(0-31): 32 x TransformerBlock(
(attention): Attention(
(wq): ColumnParallelLinear()
(wk): ColumnParallelLinear()
(wv): ColumnParallelLinear()
(wo): RowParallelLinear()
)
(feed_forward): FeedForward(
(w1): ColumnParallelLinear()
(w2): RowParallelLinear()
(w3): ColumnParallelLinear()
)
(attention_norm): RMSNorm()
(ffn_norm): RMSNorm()
)
)
(norm): RMSNorm()
(output): ColumnParallelLinear()
)
模型整体结构图:
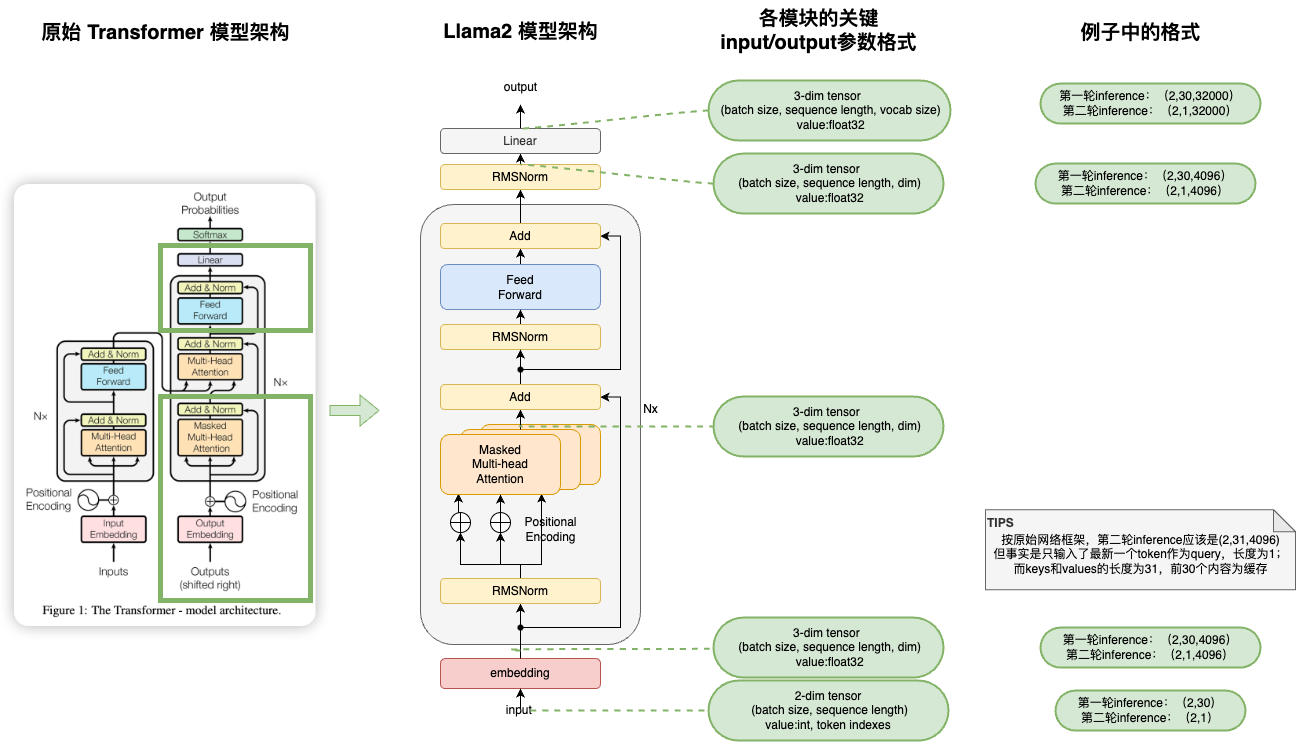
https://drive.google.com/file/d/1UxYd8RPmtXTCvPabi8Kg1RmpqyvQvelj/view?usp=sharing
Attention模块:
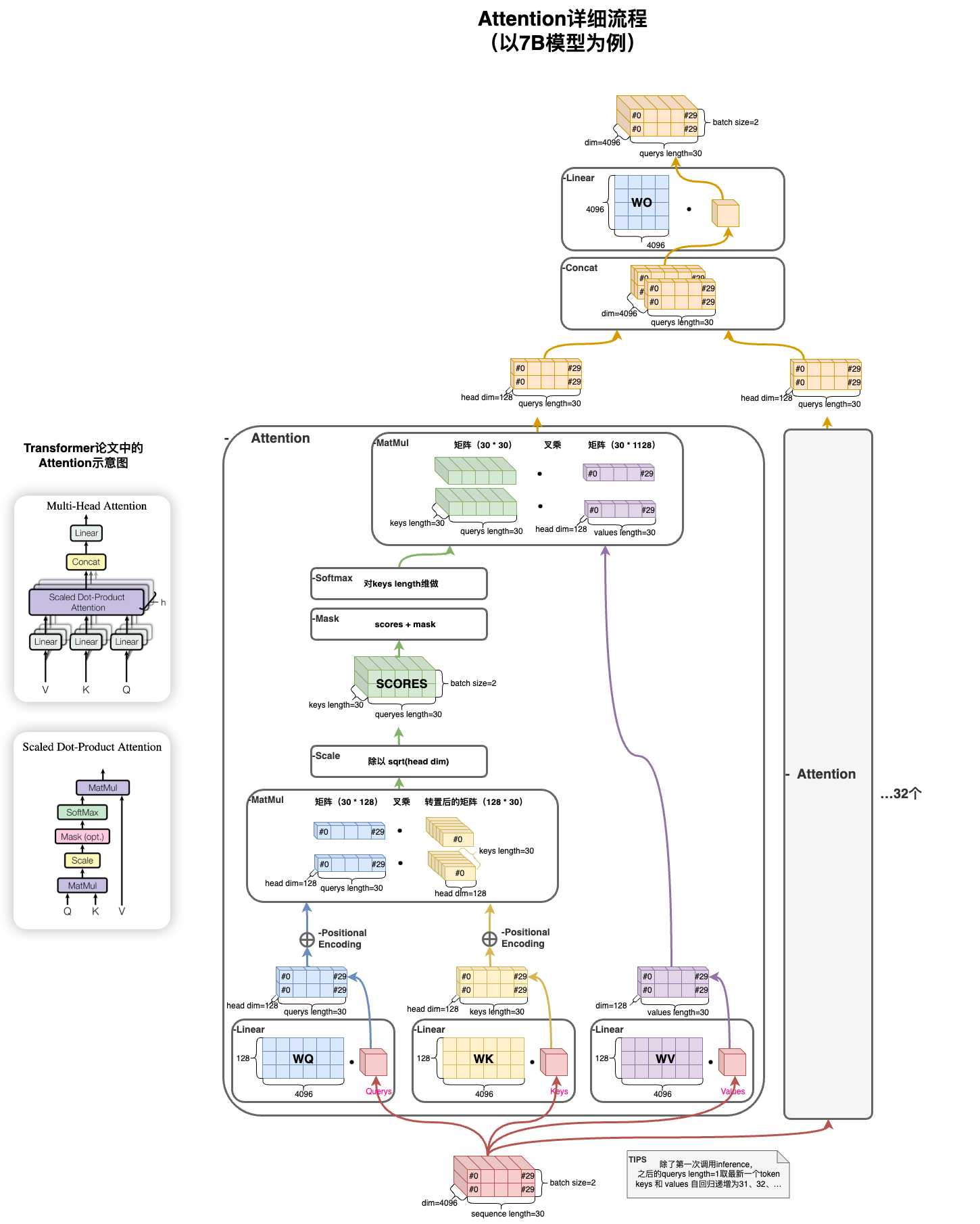
https://drive.google.com/file/d/140FeGo8ld1Ozg8UCNsEZNwM9ds7DB9r-/view?usp=sharing
模型load
将存在consolidated.00.pth这个checkpoint文件中的weights数据反序列化成python数据结构。 整体结果是一个dict,里面有292个tensor,292 = 4 + 32层 * 9个module模块,数据格式都是torch.bfloat16
| value | Tensor size |
|---|---|
| ‘tok_embeddings.weight’ | (32000, 4096) |
| ‘layers.0.attention.wq.weight’ | (4096, 4096) |
| ‘layers.0.attention.wk.weight’ | (4096, 4096) |
| ‘layers.0.attention.wv.weight’ | (4096, 4096) |
| ‘layers.0.attention.wo.weight’ | (4096, 4096) |
| ‘layers.0.feed_forward.w1.weight’ | (11008, 4096) |
| ‘layers.0.feed_forward.w2.weight’ | (4096, 11008) |
| ‘layers.0.feed_forward.w3.weight’ | (11008, 4096) |
| ‘layers.0.attention_norm.weight’ | (4096,) |
| ‘layers.0.ffn_norm.weight’ | (4096,) |
| ‘norm.weight’ | (4096,) |
| ‘output.weight’ | (32000, 4096) |
| ‘rope.freqs’ | (64,) |
一些模型设计细节参考Transformer学习笔记
![]()
![]()
代码及注释
example_chat_completion.py
# -*- coding: utf-8 -*-
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
from typing import Optional
import fire
from llama import Llama
import os
import torch
os.environ['RANK'] = '0'
os.environ['WORLD_SIZE'] = '1'
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '8888'
def main(
ckpt_dir: str,
tokenizer_path: str,
temperature: float = 0.6,
top_p: float = 0.9,
max_seq_len: int = 512,
max_batch_size: int = 4,
max_gen_len: Optional[int] =50
):
generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
)
dialogs = [
[
{"role": "user", "content": "what is the recipe of mayonnaise?"}
],
[
{"role": "user", "content": "I am going to Paris, what should I see?"},
{
"role": "assistant",
"content": """\
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:
1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.
2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.
3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.
These are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world.""",
},
{"role": "user", "content": "What is so great about #1?"},
],
[
{"role": "system", "content": "Always answer with Haiku"},
{"role": "user", "content": "I am going to Paris, what should I see?"},
],
[
{
"role": "system",
"content": "Always answer with emojis",
},
{"role": "user", "content": "How to go from Beijing to NY?"},
],
]
dialogs1=[
[
{"role": "system", "content": "Always answer by Chinese"},
{"role": "user", "content": "I am going to Beijing, what should I see?"}
],
[
{"role": "system", "content": "Be cute"},
{"role": "user", "content": "What is PyTorch?"}
]
]
print(f"[example_chat_completion] calling generator.chat_completion.\
max_gen_len={max_gen_len}, temperature={temperature}, top_p={top_p}")
results = generator.chat_completion(
dialogs1, # type: ignore
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
logprobs=False,
)
print(f"\n=============results=====================\n {results}")
print("\n==================================\n")
for dialog, result in zip(dialogs1, results):
for msg in dialog:
print(f"{msg['role'].capitalize()}: {msg['content']}\n")
print(
f"> {result['generation']['role'].capitalize()}: {result['generation']['content']}"
)
print("\n==================================\n")
if __name__ == "__main__":
# --ckpt_dir llama-2-7b-chat/ --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 4
fire.Fire(main(ckpt_dir="llama-2-7b-chat/", tokenizer_path="tokenizer.model"))
generation.py
# -*- coding: utf-8 -*-
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
import json
import logging
import os
import sys
import time
from pathlib import Path
from typing import List, Literal, Optional, Tuple, TypedDict
import logging
import torch
import torch.nn.functional as F
# fire是一个并发执行框架,可忽略
from fairscale.nn.model_parallel.initialize import (
get_model_parallel_rank,
initialize_model_parallel,
model_parallel_is_initialized,
)
from llama.model import ModelArgs, Transformer
from llama.tokenizer import Tokenizer
logger = logging.getLogger()
# user代表用户想问的问题
# system是prompt,可以参考下面的DEFAULT_SYSTEM_PROMPT
# assistant代表回复方
Role = Literal["system", "user", "assistant"]
class Message(TypedDict):
role: Role
content: str
class CompletionPrediction(TypedDict, total=False):
generation: str
tokens: List[str] # not required
logprobs: List[float] # not required
class ChatPrediction(TypedDict, total=False):
generation: Message
tokens: List[str] # not required
logprobs: List[float] # not required
Dialog = List[Message]
# 特殊token,标识system prompt 和 一段对话输入instance
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
DEFAULT_SYSTEM_PROMPT = """\
You are a helpful, respectful and honest assistant. \
Always answer as helpfully as possible, while being safe. \
Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. \
Please ensure that your responses are socially unbiased and positive in nature.\
If a question does not make any sense, or is not factually coherent,\
explain why instead of answering something not correct. \
If you don't know the answer to a question, please don't share false information."""
class Llama:
@staticmethod
def build(
ckpt_dir: str,
tokenizer_path: str,
max_seq_len: int,
max_batch_size: int,
model_parallel_size: Optional[int] = None,
) -> "Llama":
print(f"[Llama.build]input params ckpt_dir={ckpt_dir}, tokenizer_path={tokenizer_path}, max_seq_len={max_seq_len}, max_batch_size={max_batch_size}, model_parallel_size={model_parallel_size}")
if not torch.distributed.is_initialized():
#torch.distributed.init_process_group("nccl")
torch.distributed.init_process_group("gloo")
if not model_parallel_is_initialized():
if model_parallel_size is None:
model_parallel_size = int(os.environ.get("WORLD_SIZE", 1))
initialize_model_parallel(model_parallel_size)
local_rank = int(os.environ.get("LOCAL_RANK", 0))
#torch.cuda.set_device(local_rank)
# seed must be the same in all processes
torch.manual_seed(1)
if local_rank > 0:
sys.stdout = open(os.devnull, "w")
start_time = time.time()
checkpoints = sorted(Path(ckpt_dir).glob("*.pth"))
assert len(checkpoints) > 0, f"no checkpoint files found in {ckpt_dir}"
# .pth文件的个数要与 world size 一样。7B的只有一个文件。
# 如果要并行inference模型,在保存模型文件的时候就要分开保存多个。
assert model_parallel_size == len(
checkpoints
), f"Loading a checkpoint for MP={len(checkpoints)} but world size is {model_parallel_size}"
ckpt_path = checkpoints[get_model_parallel_rank()]
# 加载模型文件。之前的代码默认都是用gpu的,修改过。
checkpoint = torch.load(ckpt_path, map_location="cpu")
with open(Path(ckpt_dir) / "params.json", "r") as f:
params = json.loads(f.read())
model_args: ModelArgs = ModelArgs(
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
**params,
)
#加载Tokenizer和模型
tokenizer = Tokenizer(model_path=tokenizer_path)
model_args.vocab_size = tokenizer.n_words
torch.set_default_tensor_type(torch.FloatTensor)
model = Transformer(model_args)
model.load_state_dict(checkpoint, strict=False)
print(f"Loaded in {time.time() - start_time:.2f} seconds")
return Llama(model, tokenizer)
def __init__(self, model: Transformer, tokenizer: Tokenizer):
self.model = model
self.tokenizer = tokenizer
@torch.inference_mode()
def generate(
self,
prompt_tokens: List[List[int]],
max_gen_len: int,
temperature: float = 0.6,
top_p: float = 0.9,
logprobs: bool = False,
echo: bool = False,
) -> Tuple[List[List[int]], Optional[List[List[float]]]]:
params = self.model.params
bsz = len(prompt_tokens)
# batch size不应超过模型的最大batch size
assert bsz <= params.max_batch_size, (bsz, params.max_batch_size)
# 计算所有batch中,token list的最小和最大长度。
# total_len是整体长度,受max_seq_len和max_gen_len限制。当max_gen_len=50时,值为50+39=89;当max_gen_len=500时,值为max_seq_len=512
min_prompt_len = min(len(t) for t in prompt_tokens)
max_prompt_len = max(len(t) for t in prompt_tokens)
assert max_prompt_len <= params.max_seq_len
total_len = min(params.max_seq_len, max_gen_len + max_prompt_len)
# 获取填充ID,通常用于扩展序列到固定长度,此处的值为-1
pad_id = self.tokenizer.pad_id
# 创建一个全为-1的tensor,大小为(batch size, total_len)即(2,89)
tokens = torch.full((bsz, total_len), pad_id, dtype=torch.long, device="cpu")
# 然后把prompt_tokens塞进去
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t, dtype=torch.long, device="cpu")
# 如果要反馈生成的token的概率,那么生成一个全为0的tensor,大小和tokens一样,也是(2,89)
if logprobs:
token_logprobs = torch.zeros_like(tokens, dtype=torch.float)
prev_pos = 0
# 初始化一个tensor来标记是否达到eos,大小为batch size即2,值先都是false
eos_reached = torch.tensor([False] * bsz, device="cpu")
# 大小为(2,89), 有输入token的地方是true,-1的地方是mask
input_text_mask = tokens != pad_id
# 所有batch的生成都从最小长度+1处开始。例子中为30
for cur_pos in range(min_prompt_len, total_len):
# logits是模型的输出。
# 第一个循环输出size是(2,30,32000),对每一个输入token,都预测了它的下一个token,但在inference的时候只用最后一个。
# 后面都是(2,1,32000),model里已经缓存了上文的输入。输出代表输入token的下一个token
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if logprobs:
# 训练的时候有意义,算预测输出logits和真实token之间的交叉熵,
token_logprobs[:, prev_pos + 1 : cur_pos + 1] = -F.cross_entropy(
input=logits.transpose(1, 2),
target=tokens[:, prev_pos + 1 : cur_pos + 1],
reduction="none",
ignore_index=pad_id,
)
if temperature > 0:
#计算32000个可能的token里,每一个的softmax概率,然后按top_p概率阈值取next_token
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
next_token = self.sample_top_p(probs, top_p)
else:
#找最大的
next_token = torch.argmax(logits[:, -1], dim=-1)
next_token = next_token.reshape(-1)
# 只替换prompt结束了的地方的token。
# 例子中,第一个batch的prompt长度为30,在第一次循环中就会用生成的token来填充第31个位置;但第二个batch的prompt长度为39,就不会替换
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
tokens[:, cur_pos] = next_token
# 判断是否生成了eos即生成结束。比如系统prompt是"只用是和否回答",生成会很短。
eos_reached |= (~input_text_mask[:, cur_pos]) & (
next_token == self.tokenizer.eos_id
)
prev_pos = cur_pos
if all(eos_reached):
break
if logprobs:
token_logprobs = token_logprobs.tolist()
out_tokens, out_logprobs = [], []
for i, toks in enumerate(tokens.tolist()):
# cut to max gen len
start = 0 if echo else len(prompt_tokens[i])
toks = toks[start : len(prompt_tokens[i]) + max_gen_len]
probs = None
if logprobs:
probs = token_logprobs[i][start : len(prompt_tokens[i]) + max_gen_len]
# cut to eos tok if any
if self.tokenizer.eos_id in toks:
eos_idx = toks.index(self.tokenizer.eos_id)
toks = toks[:eos_idx]
probs = probs[:eos_idx] if logprobs else None
out_tokens.append(toks)
out_logprobs.append(probs)
return (out_tokens, out_logprobs if logprobs else None)
def text_completion(
self,
prompts: List[str],
temperature: float = 0.6,
top_p: float = 0.9,
max_gen_len: Optional[int] = None,
logprobs: bool = False,
echo: bool = False,
) -> List[CompletionPrediction]:
if max_gen_len is None:
max_gen_len = self.model.params.max_seq_len - 1
prompt_tokens = [self.tokenizer.encode(x, bos=True, eos=False) for x in prompts]
generation_tokens, generation_logprobs = self.generate(
prompt_tokens=prompt_tokens,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
logprobs=logprobs,
echo=echo,
)
if logprobs:
return [
{
"generation": self.tokenizer.decode(t),
"tokens": [self.tokenizer.decode(x) for x in t],
"logprobs": logprobs_i,
}
for t, logprobs_i in zip(generation_tokens, generation_logprobs)
]
return [{"generation": self.tokenizer.decode(t)} for t in generation_tokens]
def chat_completion(
self,
dialogs: List[Dialog],
temperature: float = 0.6,
top_p: float = 0.9,
max_gen_len: Optional[int] = None,
logprobs: bool = False,
) -> List[ChatPrediction]:
if max_gen_len is None:
max_gen_len = self.model.params.max_seq_len - 1
prompt_tokens = []
for dialog in dialogs:
# 如果第一块儿内容不是sys系统prompt,则补一个默认的
# 然后把这段信息塞到第一个user的content里。
if dialog[0]["role"] != "system":
dialog = [
{
"role": "system",
"content": DEFAULT_SYSTEM_PROMPT,
}
] + dialog
dialog = [
{
"role": dialog[1]["role"],
"content": B_SYS
+ dialog[0]["content"]
+ E_SYS
+ dialog[1]["content"],
}
] + dialog[2:]
#需要dialog偶数位置上的消息的角色是user、奇数位置上的消息的角色是assistant
assert all([msg["role"] == "user" for msg in dialog[::2]]) and all(
[msg["role"] == "assistant" for msg in dialog[1::2]]
), (
"model only supports 'system', 'user' and 'assistant' roles, "
"starting with 'system', then 'user' and alternating (u/a/u/a/u...)"
)
dialog_tokens: List[int] = sum(
[
self.tokenizer.encode(
f"{B_INST} {(prompt['content']).strip()} {E_INST} {(answer['content']).strip()} ",
bos=True,
eos=True,
)
for prompt, answer in zip(
dialog[::2],
dialog[1::2],
)
],
[],
)
assert (
dialog[-1]["role"] == "user"
), f"Last message must be from user, got {dialog[-1]['role']}"
dialog_tokens += self.tokenizer.encode(
f"{B_INST} {(dialog[-1]['content']).strip()} {E_INST}",
bos=True,
eos=False,
)
prompt_tokens.append(dialog_tokens)
print(f"[generation-chat_completion] prompt_tokens={prompt_tokens}")
generation_tokens, generation_logprobs = self.generate(
prompt_tokens=prompt_tokens,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
logprobs=logprobs,
)
print(f"[generation-chat_completion] generate result ={generation_tokens}, generation_logprobs={generation_logprobs}")
if logprobs:
ret = [
{
"generation": {
"role": "assistant",
"content": self.tokenizer.decode(t),
},
"tokens": [self.tokenizer.decode(x) for x in t],
"logprobs": logprobs_i,
}
for t, logprobs_i in zip(generation_tokens, generation_logprobs)
]
return ret
ret = [
{"generation": {"role": "assistant", "content": self.tokenizer.decode(t)}}
for t in generation_tokens
]
return ret
# 输出累积概率在p以上的tokens
def sample_top_p(self, probs, p):
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
next_token = torch.multinomial(probs_sort, num_samples=1)
next_token = torch.gather(probs_idx, -1, next_token)
# 打印top 5 以及其概率
top_5_probs_idx = probs_idx[:, 0:5]
top_5_probs = probs_sort[:, 0:5]
for x,y in zip(top_5_probs_idx,top_5_probs):
print(f'[sample_top_p] output top5 token: {self.tokenizer.decode(x.tolist()) }, probs: {y.tolist()}')
return next_token
model.py
# -*- coding: utf-8 -*-
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
import math
from dataclasses import dataclass
from typing import Any, Optional, Tuple
import fairscale.nn.model_parallel.initialize as fs_init
import torch
import torch.nn.functional as F
from fairscale.nn.model_parallel.layers import (
ColumnParallelLinear,
ParallelEmbedding,
RowParallelLinear,
)
from torch import nn
import logging
logger = logging.getLogger(__name__)
# 7B的参数: {"dim": 4096, "multiple_of": 256, "n_heads": 32, "n_layers": 32, "norm_eps": 1e-06, "vocab_size": -1}
# dim维度,就是一个token会被表征成多长的一个向量
# n_layers层数,7B是32层
# multi-head多头的个数,这个就像不同的卷积核在学习不同的特征一样,相同的q和k,也在通过多个head学习他们不同的关系
# vocab_size词表大小,gpt4是10w,llama2是
@dataclass
class ModelArgs:
dim: int = 4096
n_layers: int = 32
n_heads: int = 32
n_kv_heads: Optional[int] = None
vocab_size: int = -1 # defined later by tokenizer
multiple_of: int = 256 # make SwiGLU hidden layer size multiple of large power of 2
ffn_dim_multiplier: Optional[float] = None
norm_eps: float = 1e-5
#TODO 这儿的batch size是啥
max_batch_size: int = 32
max_seq_len: int = 2048
#Norm是做归一化,一堆数放一块儿算出均值和方差,然后每一个值都减去均值,除以方差,这样这一堆数就变成均值为0、方差为1了
#Batch Normalization (BN)、Layer Normalization (LN)、Group Normalization (GN)、Instance Norm(IN)是取数的方法不一样。
#LayerNorm是对一个样本的所有值算norm,在例子里,就是分别对两个batch的30*4096个数算。
#RMS是计算公式不一样,没有减去均值,只除了方差。
#特别的是,此处的输出是乘了个(4096,) weight的
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
#算位置编码
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
# 结果是一个 dim//2=64 的list
# torch.arange(0, dim, 2)[: (dim // 2)].float() 的结果是: tensor([ 0., 2., 4., 6., 8., 10., 。。。, 120., 122., 124., 126.])
# 每个维度的频率都是之前维度频率的一个固定倍数,这样可以保证在不同位置产生不同的位置编码
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
#长度是max_seq_len * 2,例子中为512*2=1024.
# t的值为 [0,1,2,...,1022,1023]
t = torch.arange(end, device=freqs.device) # type: ignore
# freqs和t算外积(每一个元素都是对应的t值与freqs值的乘积)
# 结果是(1024,64)大小的tensor
freqs = torch.outer(t, freqs).float() # type: ignore
# 使用torch.polar函数来根据极坐标生成复数。这里,torch.ones_like(freqs)为复数的模(magnitude),而freqs则为复数的辐角(angle),输出freqs_cis是一个复数tensor。
freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
return freqs_cis
# resharp freqs_cis,使其能够与x做乘法
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
ndim = x.ndim
assert 0 <= 1 < ndim
#确保freqs_cis的形状与x的第二和最后一个维度匹配。
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
#这里,我们构建一个新的形状列表。对于x的每个维度:
# 如果它是第二个维度(索引为1)或是最后一个维度,我们将它的大小添加到新形状中。
# 对于其他维度,只添加一个1。
# 这确保了在broadcast时,freqs_cis与x在第二个和最后一个维度上是相对应的,而在其他维度上,freqs_cis只有一个大小。
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
# 乘位置编码
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
# xq和xk最后两维的32,128,转成复数表达,最终xq_和xk_的最后两维size是32,64,整体size是(batch_size,sql_len,32,64)
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
#freqs_cis原本size是(sql_len,64),其中最后一维是复数。经过resharp,size变成了(1,sql_len,1,64)
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
#xq_和xk_与freqs_cis进行逐元素乘法,最后再把复数拆开,形状又变回(batch_size,sql_len,32,128)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
#填缝
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bs, slen, n_kv_heads, n_rep, head_dim)
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).to("cpu")
self.cache_v = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).to("cpu")
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
bsz, seqlen, _ = x.shape
# 此处的q、k、v都是x,即self-attention,算每一个q和每一个k的相似度作为v的权重,再加权输出。
# xq, xk, xv是对x最后一维做ColumnLinear计算后的结果,权重矩阵Wq、Wk、Wv都是(4096, 4096)的
# 例子中,第一轮xq, xk, xv的size都是(2,30,4096)
# 但在multi-head attention中,其实是有32个 (128, 4096)的权重矩阵,分别将q k v投影成32个128维的向量。
# 所以在做完乘积后,通过view操作将xq, xk, xv都拆成了(2,30,32,128)的tensor
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
# 乘位置编码
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
# 更新缓存
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
# keys和values是从0到最新的输入
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# repeat k/v heads if n_kv_heads < n_heads
keys = repeat_kv(keys, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)
#第二维和第三维换位置,要逐个head来计算(seqlen, head_dim)size的q k v了
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2)
values = values.transpose(1, 2)
#先把q和keys做点乘,第一轮乘出来的结果是(2,32,30,30)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
#sql_lensize的三角形mask,把score遮掉一半,即每一个query只能看到它前面的keys
#除了第一轮,后面的q就只有增量一个token,就不需要mask了
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
#对最后一维做softmax,即each q和哪些keys的相似度高,对应score值就大,所有值加一起为1
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
#scores作为权重和values点乘输出。(30,30)dot(30,128),输出为
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
# n_local_heads和seqlen换回来,最后两维合并起来,最终输出是(bsz, seqlen, dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
# wo是Row Linear,(4096,4096)
return self.wo(output)
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
ffn_dim_multiplier: Optional[float],
):
super().__init__()
# 入参hidden_dim=4*dim,例子中为4*4096
hidden_dim = int(2 * hidden_dim / 3)
# custom dim factor multiplier
if ffn_dim_multiplier is not None:
hidden_dim = int(ffn_dim_multiplier * hidden_dim)
# multiple_of一般用在GPU场景下,确保序列的长度是某个数(例如8、16、32等)的倍数。这通常是通过对输入序列进行填充来实现的。
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
# (11008, 4096)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
#(4096,11008)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
# (11008, 4096)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
# 先把4096输入x通过w1投影成11008维向量,然后算Sigmoid激活函数,F.silu(self.w1(x))输出为(batch_size,seqlen,11008)
# 然后把4096输入x通过w3投影成11008维向量,self.w3(x)输出为(batch_size,seqlen,11008)
# 通过w3将输出乘回成4096维
return self.w2(F.silu(self.w1(x)) * self.w3(x))
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
# __init__这个过程里都没有加载weight,都是在准备模型的数据结构
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim,
hidden_dim=4 * args.dim,
multiple_of=args.multiple_of,
ffn_dim_multiplier=args.ffn_dim_multiplier,
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
# 残差连接,attention(x)算完后再把x加回来作为输出
h = x + self.attention.forward(
self.attention_norm(x), start_pos, freqs_cis, mask
)
# 残差连接,feed_forward(h)算完后再把h加回来作为输出
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
# __init__这个过程里都没有加载weight,都是在准备模型的数据结构
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
# 位置编码。例子中dim=4096 n_heads=32,4096//32 =128,max_seq_len=512
self.freqs_cis = precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
# 将tokens转换为embedding,这是一个简单的查找表操作,就是把"answer"对应的token ID"1234"变成一个4096维的向量。具体映射表是weights的一部分
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
# freqs_cis原大小为(1024,64),这里取start_pos开始,长度为seqlen的子序列,即输入token的位置编码
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
# 创建一个形状为 (1, 1, seqlen, seqlen) 的张量,全部填充为负无穷,只保留下三角形矩阵,后续会用这个mask来遮挡input,以实现Transformer decoder中的那个"masked"
mask = torch.full(
(1, 1, seqlen, seqlen), float("-inf"), device=tokens.device
)
mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)
for layer in self.layers:
# 将嵌入、开始位置、频率和mask输入到层中,并得到输出
h = layer(h, start_pos, freqs_cis, mask)
# 最后对输出再做一层正则化
h = self.norm(h)
# 然后全连接输出。此处的output是一个ColumnLinear,即一个(32000, 4096)的权重矩阵列乘h,最终输出的是一个32000维的行向量
# RowLinear: 一个行向量r和一个矩阵M,r * M。ColumnLinear: 一个列向量c和一个矩阵M,M * c
output = self.output(h).float()
return output
tokenizer.py
# -*- coding: utf-8 -*-
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
import os
from logging import getLogger
from typing import List
from sentencepiece import SentencePieceProcessor
logger = getLogger()
class Tokenizer:
def __init__(self, model_path: str):
# reload tokenizer
assert os.path.isfile(model_path), model_path
#SentencePiece库是google的,能根据输入文本自动生成词汇表。这里复用了这个库做的token化
self.sp_model = SentencePieceProcessor(model_file=model_path)
print(f"Reloaded SentencePiece model from {model_path}")
# BOS / EOS token IDs ,beginning of sentence、end of sentence、padding
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.pad_id()
print(
f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id} - PAD ID: {self.pad_id}"
)
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
def encode(self, s: str, bos: bool, eos: bool) -> List[int]:
# 有些细节比较难受,比如定义了特殊符号[INST]、<<SYS>>,但是他们都被分词成了多个token,它们的组合关系靠学出来的。('▁[', 518), ('INST', 25580), (']', 29962)
print( f"[Tokenizer-encode] input str={s}, bos={bos}, eos={eos}")
assert type(s) is str
t = self.sp_model.encode(s)
t_tokens = self.sp_model.encode_as_pieces(s)
pairs=list(zip(t_tokens, t))
#print( f"[Tokenizer-encode] final result token ids={t}, final result token pieces={t_tokens}")
print( f"[Tokenizer-encode] final result ={pairs}")
if bos:
t = [self.bos_id] + t
if eos:
t = t + [self.eos_id]
return t
def decode(self, t: List[int]) -> str:
return self.sp_model.decode(t)
其他
【1】
https://github.com/ggerganov/llama.cpp
能通过quantization压缩模型(113G->36G)并跑在M2芯片上,inference速度大幅提高
./main -m ./models/llama-2-70b-chat/ggml-model-q4_0.gguf -n 256 –repeat_penalty 1.0 –color -i -r “User:” -f prompts/chat-with-bob.txt
./main -m ./models/llama-2-70b-chat/ggml-model-q4_0.gguf -n 256 -r “User:” –color -p “what is pytorch”
【2】
一个典型的GPT-like模型training过程可以参考教学视频(16:00开始):https://www.youtube.com/watch?v=kCc8FmEb1nY

