大部分翻译借鉴自网络,做了读书笔记
Large-scale cluster management at Google with Borg
摘要
Google’s Borg system is a cluster manager that runs hundreds of thousands of jobs, from many thousands of different applications, across a number of clusters each with up to tens of thousands of machines.
Google的Borg系统是一个集群管理器,管理着运行在多个万台机器规模集群上的来自几千个不同应用的几十万个作业。 (application定义一致,几十万对应我们SOA中的服务个数)
It achieves high utilization by combining admission control, efficient task-packing, over-commitment, and machinesharing with process-level performance isolation. It supports high-availability applications with runtime features that minimize fault-recovery time, and scheduling policies that reduce the probability of correlated failures. Borg simplifieslife for its users by offering a declarative job specificationlanguage, name service integration, real-time job monitor-ing, and tools to analyze and simulate system behavior. Borg通过准入控制、高效的任务装箱、超售、机器共享、以及进程级别的性能隔离,实现了高利用率。它为高可用应用提供了可以减少故障恢复时间的运行时特性,以及降低关联故障概率的调度策略。Borg提供了声明式的作业描述语言、域名服务集成、实时作业监控、分析和模拟系统行为的工具。这些简化了用户的使用。
We present a summary of the Borg system architecture and features, important design decisions, a quantitative analysis of some of its policy decisions, and a qualitative examination of lessons learned from a decade of operational experience with it. 本文介绍了Borg系统架构和特性,重要的设计决策,对策略选择的定量分析,以及十年来的运营经验的定性总结。
1. 简介
The cluster management system we internally call Borg admits, schedules, starts, restarts, and monitors the full range of applications that Google runs. This paper explains how.
我们内部称为Borg的集群管理系统负责接收、调度、启动、重启和监控Google所有的应用。本文介绍它是如何实现的。
Borg provides three main benefits: it (1) hides the details of resource management and failure handling so its users can focus on application development instead; (2) operates with very high reliability and availability, and supports applications that do the same; and (3) lets us run workloads across tens of thousands of machines effectively. Borg is not the first system to address these issues, but it’s one of the few operating at this scale, with this degree of resiliency and completeness. This paper is organized around these topics, concluding with a set of qualitative observations we have made from operating Borg in production for more than a decade.
Borg提供了三个主要的好处:(1)隐藏资源管理和故障处理细节,使用户可以专注于应用开发;(2)高可靠和高可用的运维,并支持应用程序也能够如此;(3)让我们可以在几万台机器上高效地运行负载。Borg不是第一个涉及这些问题的系统,但它是少有的运行在如此大规模,具有弹性且完整的系统之一。本文围绕这些主题来编写,总结了十多年来我们在生产环境运行Borg的一些定性观察。
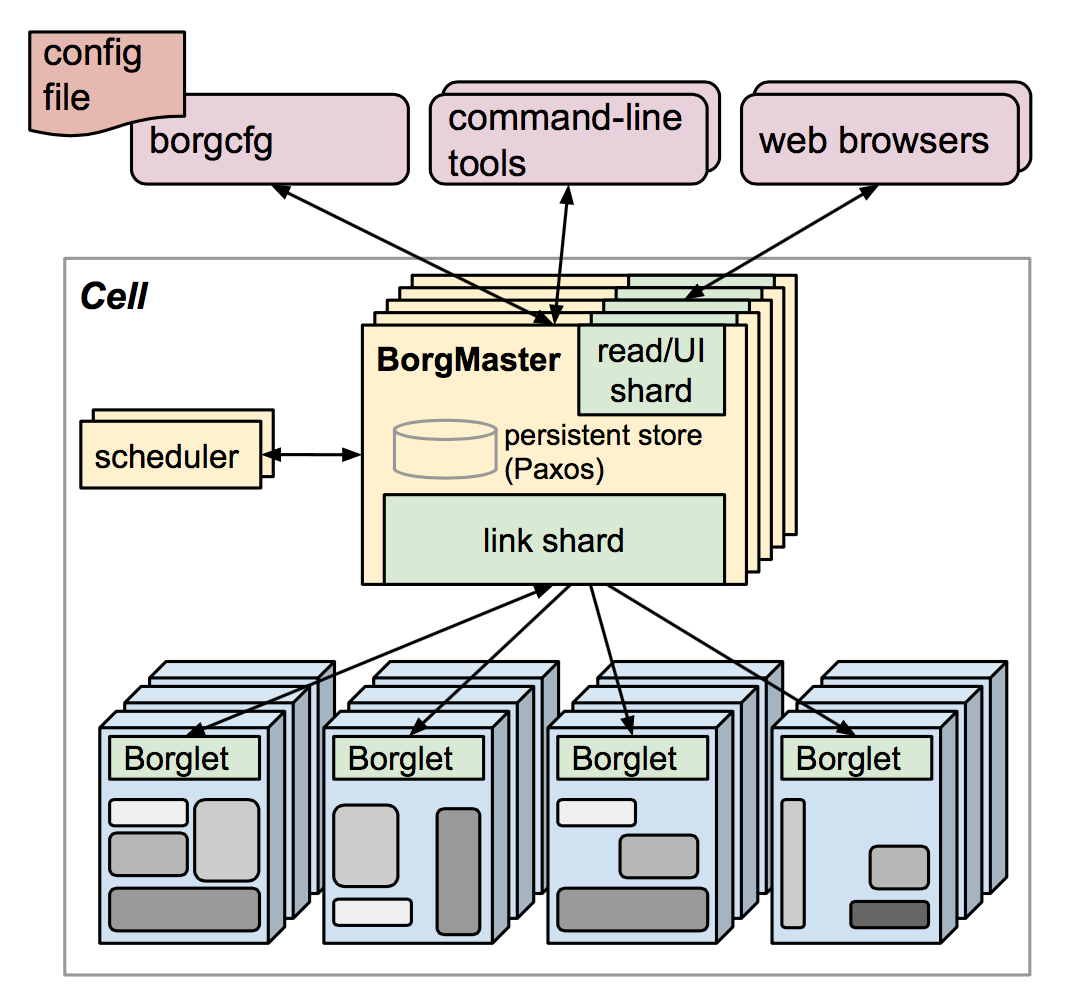
图1. Borg的架构。图中只画出了数千个工作节点的很小一部分
2. 用户视角 The user perspective
Borg’s users are Google developers and system administrators (site reliability engineers or SREs) that run Google’s applications and services. Users submit their work to Borg in the form of jobs, each of which consists of one or more tasks that all run the same program (binary). Each job runs in one Borg cell, a set of machines that are managed as a unit. The remainder of this section describes the main features exposed in the user view of Borg.
Borg的用户是Google的RD和SRE。用户以作业Jobs的方式将他们的工作提交给Borg。作业job由一个或多个任务Tasks组成,每个task执行相同的二进制程序 (task间互为replica)。每个作业job都运行在一个Borg单元Cell里。Cell是一组机器的管理单元。下面的小节将介绍用户视角看到的Borg系统的主要特性。
2.1 工作负载 Workload
Borg cells run a heterogenous workload with two main parts. The first is long-running services that should “never” go down, and handle short-lived latency-sensitive requests (a few μs to a few hundred ms). Such services are used for end-user-facing products such as Gmail, Google Docs, and web search, and for internal infrastructure services (e.g., BigTable). The second is batch jobs that take from a few seconds to a few days to complete; these are much less sensitive to short-term performance fluctuations. The workload mix varies across cells, which run different mixes of applications depending on their major tenants (e.g., some cells are quite batch-intensive), and also varies over time: batch jobs
Borg Cell主要运行2种异构的工作负载。第一种是应该永不停止的长期运行的服务,处理持续时间较短但对延迟敏感的请求(从几微秒到几百毫秒)。这些服务用于面向最终用户的产品,如Gmail、Google Docs、网页搜索,以及内部基础设施服务(例如Bigtable)。第二种是批处理作业,执行时间从几秒到几天,对短期性能波动不敏感。这2种负载在不同Cell中的比例不同,取决于其主要租户(例如,有些Cell就以批处理作业为主)。工作负载也随时间变化:批处理作业不断提交或结束,而很多面向终端用户的服务表现出昼夜周期性的使用模式。Borg需要都处理好这些情况。(在线和离线集群都是Brog在统一管理的,没有区分开)
A representative Borg workload can be found in a publicly-available month-long trace from May 2011 [80], which has been extensively analyzed (e.g., [68] and [1, 26, 27, 57]).
Borg的代表性负载是一个公开的2011年5月整月的记录数据集[80]。这个数据集已经得到了广泛的分析[1, 26, 27, 57, 68]。
Many application frameworks have been built on top of Borg over the last few years, including our internal MapReduce system [23], FlumeJava [18], Millwheel [3], and Pregel [59]. Most of these have a controller that submits a master job and one or more worker jobs; the first two play a similar role to YARN’s application manager [76]. Our distributed storage systems such as GFS [34] and its successor CFS, Bigtable [19], and Megastore [8] all run on Borg.
最近几年,以Borg为基础构建了很多应用框架,包括我们内部的MapReduce系统[23]、FlumeJava[18]、Millwheel[3]和Pregel[59]。这些框架大多有一个控制器来提交Master Job,还有多个Worker Job。前两个框架类似于YARN的应用管理器[76]。我们的分布式存储系统,例如GFS[34]和它的后继者CFS、Bigtable[19]、以及Megastore[8],都是运行在Borg上的。
For this paper, we classify higher-priority Borg jobs as “production” (prod) ones, and the rest as “non-production” (non-prod). Most long-running server jobs are prod; most batch jobs are non-prod. In a representative cell, prod jobs are allocated about 70% of the total CPU resources and represent about 60% of the total CPU usage; they are allocated about 55% of the total memory and represent about 85% of the total memory usage. The discrepancies between allocation and usage will prove important in §5.5.
本文中,我们把高优先级的Borg作业称为为生产作业(prod),其它的则是非生产的(non-prod)。大多数长期服务是prod的,大部分批处理作业是non-prod的。一个典型Cell里,prod作业申请了约70%的CPU资源,使用了约60%;申请了约55%的内存资源,使用了约85%。§5.5节将具体阐述分配量与使用量间差异的重要性。
2.2 集群(Cluster)和单元(Cell)
The machines in a cell belong to a single cluster, defined by the high-performance datacenter-scale network fabric that connects them. A cluster lives inside a single datacenter building, and a collection of buildings makes up a site. A cluster usually hosts one large cell and may have a few smaller-scale test or special-purpose cells. We assiduously avoid any single point of failure.
一个Cell里的机器属于同一个集群cluster。集群由数据中心级的高性能光纤的组网来定义。一个集群位于一个数据中心的一栋建筑内,而一个数据中心有多栋建筑(注:这些关系会有少数例外情况)。一个集群通常包括一个大的Cell,还可能有一些小规模的测试用或其它特殊用途的Cell。我们尽力避免任何单点故障。(即不搞大型Cell)
Our median cell size is about 10 k machines after excluding test cells; some are much larger. The machines in a cell are heterogeneous in many dimensions: sizes (CPU, RAM, disk, network), processor type, performance, and capabilities such as an external IP address or flash storage. Borg isolates users from most of these differences by determining where in a cell to run tasks, allocating their resources, installing their programs and other dependencies, monitoring their health, and restarting them if they fail.
不计测试用的Cell,中等规模的Cell约有一万台机器;有些Cell还要大得多。Cell中的机器从多个维度看都是异构的:大小(CPU、内存,硬盘,网络)、处理器类型、性能、以及是否有外网IP地址或SSD等。Borg负责决定任务在Cell中的哪些机器上执行、为其分配资源、安装程序及依赖、监控健康状态并在失败后重启,从而使用户几乎不必关心机器异构性。
2.3 作业(Job)和任务(Task)
A Borg job’s properties include its name, owner, and the number of tasks it has. Jobs can have constraints to force its tasks to run on machines with particular attributes such as processor architecture, OS version, or an external IP address. Constraints can be hard or soft; the latter act like preferences rather than requirements. The start of a job can be deferred until a prior one finishes. A job runs in just one cell.
一个Borg 作业的属性有:名称、拥有者和任务个数。作业可以有一些约束来强制其任务运行在有特定属性的机器上,比如处理器架构、操作系统版本、是否有外网IP地址等。约束可以是硬性的或者柔性的,柔性约束表示偏好,而非需求。一个作业可以推迟到前一个作业结束后再开始(可以定义job间的依赖顺序)。一个作业只在一个Cell中运行。(有Cell容灾需求么?)
Each task maps to a set of Linux processes running in a container on a machine [62]. The vast majority of the Borg workload does not run inside virtual machines (VMs), because we don’t want to pay the cost of virtualization. Also, the system was designed at a time when we had a considerable investment in processors with no virtualization support in hardware.
每个任务对应着一组Linux进程,运行在一台机器上的一个容器内 [62]。绝大部分Borg的工作负载没有运行在虚拟机里,因为我们不想付出虚拟化的开销。而且,在Borg设计的时候,我们有很多处理器还没有硬件虚拟化功能呢。
A task has properties too, such as its resource requirements and the task’s index within the job. Most task properties are the same across all tasks in a job, but can be over-ridden – e.g., to provide task-specific command-line flags. Each resource dimension (CPU cores, RAM, disk space, disk access rate, TCP ports, etc.) is specified independently at fine granularity; we don’t impose fixed-sized buckets or slots (§5.4). Borg programs are statically linked to reduce dependencies on their runtime environment, and structured as packages of binaries and data files, whose installation is orchestrated by Borg.
任务也有一些属性,如资源需求量,在作业中的序号等。一个作业中的任务大多有相同的属性,但也可以被覆盖 —— 例如特定任务的命令行参数。各维度的资源(CPU核、内存、硬盘空间、硬盘访问速度、TCP端口(注:Borg负责管理一台机器上的可用端口并将其分配给任务)等)可以互相独立的以细粒度指定。我们不强制使用固定大小的资源桶或槽(见§5.4)。Borg运行的程序都是静态链接的(环境依赖越少越好,其实这个解法和docker思路很一致),以减少对运行环境的依赖,这些程序组织成由二进制文件和数据文件构成的包,由Borg负责安装。
Users operate on jobs by issuing remote procedure calls (RPCs) to Borg, most commonly from a command-line tool, other Borg jobs, or our monitoring systems (§2.6). Most job descriptions are written in the declarative configuration language BCL. This is a variant of GCL [12], which generates protobuf files [67], extended with some Borg-specific keywords. GCL provides lambda functions to allow calculations, and these are used by applications to adjust their configurations to their environment; tens of thousands of BCL files are over 1 k lines long, and we have accumulated tens of millions of lines of BCL. Borg job configurations have similarities to Aurora configuration files [6].
用户通过向Borg发送RPC来控制作业。RPC大多是从命令行工具、其它作业、或我们的监控系统(§2.6)发出的。大多作业描述文件使用一种声明式配置语言BCL。BCL是GCL[12]的一个变种,即增加了一些Borg专有的关键字,而GCL会生成若干protobuf文件[67]。GCL还提供了lambda函数以支持计算,这样就能让应用根据环境调整自己的配置。有上万个超过一千行的BCL配置文件,系统中累计了千万行BCL。Aurora的配置文件与Borg的作业配置 [6]相似。
Figure 2 illustrates the states that jobs and tasks go through during their lifetime.
图2展示了作业和任务整个生命周期的状态变化。
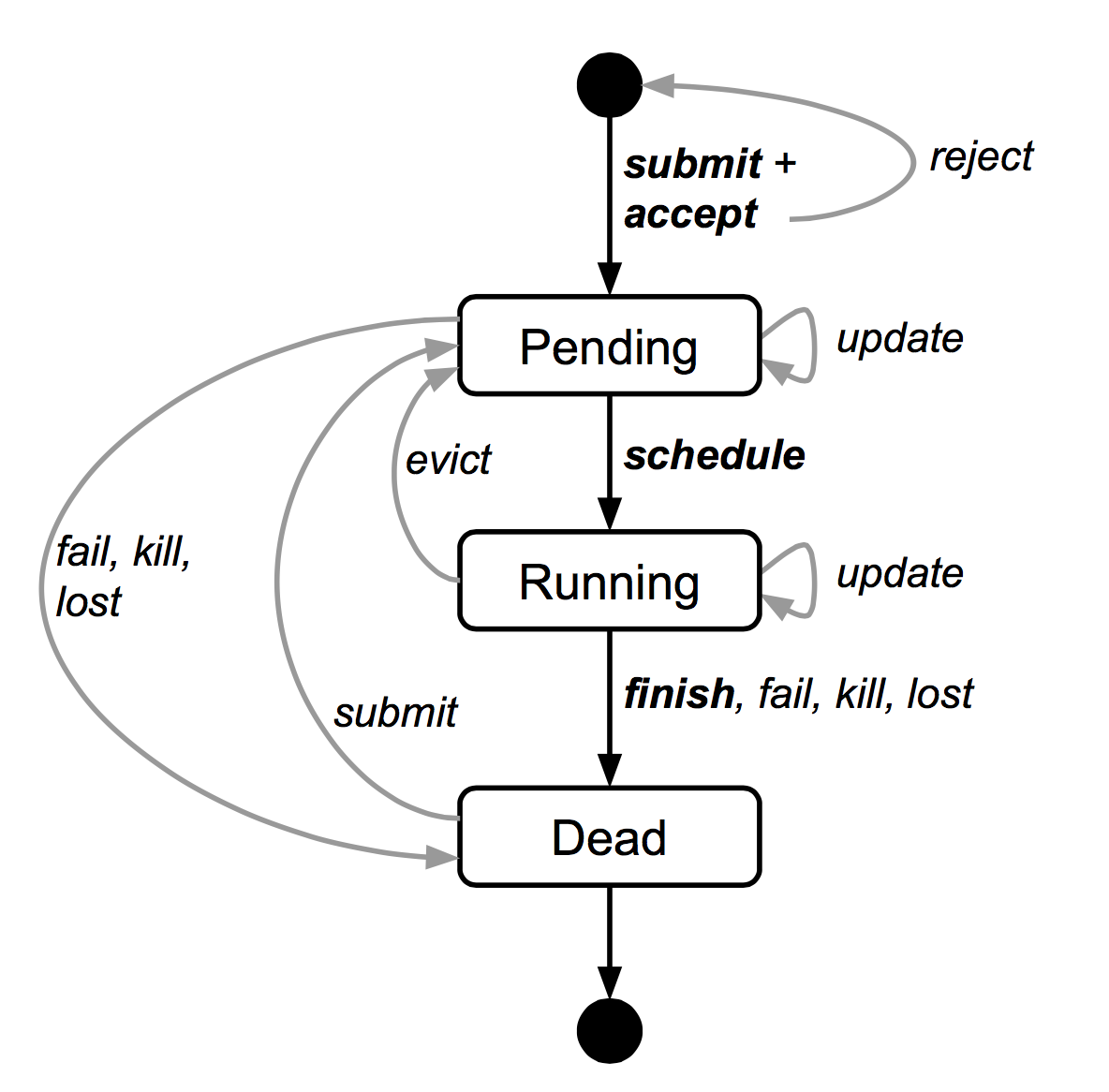
Figure 2: The state diagram for both jobs and tasks. Users can trigger submit, kill, and update transitions.
A user can change the properties of some or all of the tasks in a running job by pushing a new job configuration to Borg, and then instructing Borg to update the tasks to the new specification. This acts as a lightweight, non-atomic transaction that can easily be undone until it is closed (committed). Updates are generally done in a rolling fashion, and a limit can be imposed on the number of task disruptions (reschedules or preemptions) an update causes; any changes that would cause more disruptions are skipped.
要想在运行时改变一个作业中若干或全部任务的属性,用户可以向Borg提交一个新的作业配置,并命令Borg将任务更新到新的配置。更新是轻量的,非原子性的事务,在事务结束(提交)之前可以很容易地撤销。更新通常是滚动执行的,而且可以限制由更新导致的任务中断(被重新调度或抢占)的数量;超过限值后,变更将会被跳过。(看起来这个skip更像是个止损的动作。如果在正常情况下滚动执行更新,是不会有超过limit个数的task被中断的)
Some task updates (e.g., pushing a new binary) will always require the task to be restarted; some (e.g., increasing resource requirements or changing constraints) might make the task no longer fit on the machine, and cause it to be stopped and rescheduled; and some (e.g., changing priority) can always be done without restarting or moving the task.
一些任务更新(如更新二进制程序)需要重启任务;另外一些更新(如增加资源需求或修改约束)可能使该任务不适合运行在当前机器上,导致停止并重新调度该任务;还有一些更新(如修改优先级)总是可以进行的,不需要重启或者移动任务。
Tasks can ask to be notified via a Unix SIGTERM signal before they are preempted by a SIGKILL, so they have time to clean up, save state, finish any currently-executing requests, and decline new ones. The actual notice may be less if the preemptor sets a delay bound. In practice, a notice is delivered about 80% of the time.
任务可以要求在被Unix的SIGKILL信号立即杀死之前获得SIGTERM信号通知,这样它们还有时间清理资源、保存状态、结束当前请求、拒绝新请求。但如果抢占者设置了延迟限值,就可能来不及发通知。实践中,80%的情况下能发出通知信号。
2.4 分配(Allocs)
(?为什么要有alloc,看起来和task是对标的呀?alloc set看起来和job对标呀??)
A Borg alloc (short for allocation) is a reserved set of resources on a machine in which one or more tasks can be run; the resources remain assigned whether or not they are used. Allocs can be used to set resources aside for future tasks, to retain resources between stopping a task and starting it again, and to gather tasks from different jobs onto the same machine – e.g., a web server instance and an associated log saver task that copies the server’s URL logs from the local disk to a distributed file system. The resources of an alloc are treated in a similar way to the resources of a machine; multiple tasks running inside one share its resources. If an alloc must be relocated to another machine, its tasks are rescheduled with it.
Borg的alloc(allocation的缩写)是一台机器上的预留资源,可以用来执行一个或多个任务;不管有没有被使用,这些资源都算分配出去了。Allocs可以给将来的任务预留资源,或在任务暂停和重启的间隔保持资源,以及将不同作业的多个任务绑定在同一台机器上 —— 例如一个Web服务器实例和附加的将其URL日志从本机硬盘拷贝到分布式文件系统的日志转存任务。Alloc像一台机器那样来管理;运行在同一个Alloc内的多个任务共享其资源。如果一个Alloc需要迁移到其它机器上,那么它的任务也要跟着重新调度。
An alloc set is like a job: it is a group of allocs that reserve resources on multiple machines. Once an alloc set has been created, one or more jobs can be submitted to run in it. For brevity, we will generally use “task” to refer to an alloc or a top-level task (one outside an alloc) and “job” to refer to a job or alloc set.
一个Alloc集,即一组在多台机器上预留了资源的Alloc,类似于一个作业。一旦创建了一个Alloc集,就可以向其提交若干作业。简便起见,我们用 任务task 表示一个Alloc或者一个顶层任务(即运行在Alloc之外的任务),用 作业job 表示一个普通作业或者Alloc集。
2.5 优先级、配额和准入控制 Priority, quota, and admission control
What happens when more work shows up than can be accommodated? Our solutions for this are priority and quota.
当出现超过系统容量的工作负载会产生什么情况?我们对此的解决方案是优先级和配额。
Every job has a priority, a small positive integer. A high-priority task can obtain resources at the expense of a lower-priority one, even if that involves preempting (killing) the latter. Borg defines non-overlapping priority bands for different uses, including (in decreasing-priority order): monitoring, production, batch, and best effort (also known as testing or free). For this paper, prod jobs are the ones in the monitoring and production bands.
每个作业都有一个小的正整数表示的优先级。高优先级的任务可以优先获得资源,甚至抢占(杀死)低优先级的任务。Borg为不同用途定义了不重叠的优先级区间,包括(优先级降序):监控、生产、批处理、尽力(即测试的或免费的)。本文中,prod作业的优先级包括监控和生产两个区间。
Although a preempted task will often be rescheduled elsewhere in the cell, preemption cascades could occur if a high-priority task bumped out a slightly lower-priority one, which bumped out another slightly-lower priority task, and so on. To eliminate most of this, we disallow tasks in the production priority band to preempt one another. Fine-grained priorities are still useful in other circumstances –e.g., MapReduce master tasks run at a slightly higher priority than the workers they control, to improve their reliability.
虽然一个被抢占的任务通常会被重新调度到Cell的其它机器上,但级联抢占也可能发生:如果某个任务抢占了一个优先级稍低的任务,而后者又抢占了另一个优先级稍低的,如此往复。为避免这种情况,我们禁止生产区间的任务互相抢占。细粒度(注:相比于区间的粗粒度)的优先级在其它场景下也很有用 —— 如MapReduce的Master 任务的优先级比其管理的Worker高一点,以提高其可靠性。
Priority expresses relative importance for jobs that are running or waiting to run in a cell. Quota is used to decide which jobs to admit for scheduling. Quota is expressed as a vector of resource quantities (CPU, RAM, disk, etc.) at a given priority, for a period of time (typically months). The quantities specify the maximum amount of resources that a user’s job requests can ask for at a time (e.g., “20TiB of RAM at prod priority from now until the end of July in cell xx”). Quota-checking is part of admission control, not scheduling: jobs with insufficient quota are immediately rejected upon submission.
优先级表示了Cell中运行或等待的作业之间的相对重要性。配额(Quota)则用来决定准许哪个作业可以被调度。配额是特定优先级和时间段(典型是几个月)的一个资源向量(CPU,内存,硬盘等)。配额限制了用户的作业一次可以申请资源的最大数量(如:20TB内存,prod优先级,从现在到7月末,在xx Cell内)。配额检查是用来做准入控制的,不会延迟到调度的时候才检查:配额不足的作业提交时当即就会被拒绝。
Higher-priority quota costs more than quota at lower-priority. Production-priority quota is limited to the actual resources available in the cell, so that a user who submits a production-priority job that fits in their quota can expect it to run, modulo fragmentation and constraints. Even though we encourage users to purchase no more quota than they need, many users overbuy because it insulates them against future shortages when their application’s user base grows. We respond to this by over-selling quota at lower-priority levels: every user has infinite quota at priority zero, although this is frequently hard to exercise because resources are oversubscribed. A low-priority job may be admitted but remain pending (unscheduled) due to insufficient resources.
高优先级的配额比低优先级的成本要高。生产级的配额限定于一个Cell的物理资源量。因此,用户提交了不超过配额的生产级作业时,不考虑资源碎片和约束,可以预期这个作业一定会运行。尽管我们鼓励用户不要购买超过其需求的配额,但很多用户仍然超买了,这样他们就不用担心由于将来应用用户量增长可能导致的配额短缺。我们的应对方案是对低优先级资源配额的超售:所有用户的0优先级配额是无限的,尽管这无法实现。低优先级的作业虽然被接收了,但可能由于资源不足而一直等待。
Quota allocation is handled outside of Borg, and is intimately tied to our physical capacity planning, whose results are reflected in the price and availability of quota in different datacenters. User jobs are admitted only if they have sufficient quota at the required priority. The use of quota reduces the need for policies like Dominant Resource Fairness (DRF) [29, 35, 36, 66].
配额分配是Borg之外的系统处理的,与我们的物理容量规划紧密相关。容量规划的结果反映在各数据中心的价格和可用配额上。只有在其要求的优先级有足够的配额,用户的作业才能被接收。采用配额使得主导资源公平性(DRF)[29, 35, 36, 66]这样的策略不是那么必要了。
Borg has a capability system that gives special privileges to some users; for example, allowing administrators to delete or modify any job in the cell, or allowing a user to access restricted kernel features or Borg behaviors such as disabling resource estimation (§5.5) on their jobs.
Borg的容量系统可以给某些用户一些特殊权限。例如,允许管理员删除或修改Cell里的任意作业,或者允许某个用户操作特定的内核特性或Borg行为(如对其作业禁用资源估计。§5.5)。
2.6 命名和监控 Naming and monitoring
It’s not enough to create and place tasks: a service’s clients and other systems need to be able to find them, even after they are relocated to a new machine. To enable this, Borg creates a stable “Borg name service” (BNS) name for each task that includes the cell name, job name, and task number. Borg writes the task’s hostname and port into a consistent, highly-available file in Chubby [14] with this name, which is used by our RPC system to find the task endpoint. The BNS name also forms the basis of the task’s DNS name, so the fiftieth task in job jfoo owned by user ubar in cell cc would be reachable via 50.jfoo.ubar.cc.borg.google.com . Borg also writes job size and task health information into Chubby whenever it changes, so load balancers can see where to route requests to.
仅仅创建和部署任务是不够的:一个服务的客户端和其它系统需要能找到它们,即使该服务被重新部署到另一台机器之后。为实现该需求,Borg为每个任务创建了一个固定的BNS域名(BNS,Borg name Service),这个域名包括了Cell名,作业名称和任务序号。Borg把任务的主机名和端口写入Chubby [14]的一个持久化高可用文件里,以BNS域名为文件名。这个文件被RPC用来发现任务的实际地址。BNS域名也是任务的DNS域名的一部分,例如,cc Cell的ubar用户的jfoo 作业的第50个任务可以通过50.jfoo.ubar.cc.borg.google.com来访问。每当状态改变时,Borg还会把作业的大小和任务的健康信息写入到Chubby,这样负载均衡器就知道如何路由请求了。
Almost every task run under Borg contains a built-in HTTP server that publishes information about the health of the task and thousands of performance metrics (e.g., RPC latencies). Borg monitors the health-check URL and restarts tasks that do not respond promptly or return an HTTP error code. Other data is tracked by monitoring tools for dashboards and alerts on service level objective (SLO) violations.
几乎每个任务都有一个内置的HTTP服务器,用来发布任务的健康信息和几千个性能指标(如RPC延时)。Borg监控这些健康检查的URL,重启那些没有立刻响应或返回HTTP错误码的任务。监控工具跟踪其它数据并显示在仪表盘上,当违反服务水平目标(SLO)时报警。
A service called Sigma provides a web-based user interface (UI) through which a user can examine the state of all their jobs, a particular cell, or drill down to individual jobs and tasks to examine their resource behavior, detailed logs, execution history, and eventual fate. Our applications generate voluminous logs; these are automatically rotated to avoid running out of disk space, and preserved for a while after the task’s exit to assist with debugging. If a job is not running Borg provides a “why pending?” annotation, together with guidance on how to modify the job’s resource requests to better fit the cell. We publish guidelines for “conforming” resource shapes that are likely to schedule easily.
用户可以使用一个称为Sigma的Web界面来检查他的所有作业的状态,针对某个Cell,或者深入某个作业及任务,检查其资源使用行为、详细日志、执行历史和最终结果。我们的应用产生大量的日志,它们都会被自动的滚动以避免耗尽硬盘空间。任务退出后,日志会保留一小段时间以帮助调试。如果一个作业没有运行起来,Borg会提供一个挂起原因的注解,以及建议如何修改作业的资源请求,以使其更适合Cell。我们发布了如何使资源请求更容易被调度的指南。
Borg records all job submissions and task events, as well as detailed per-task resource usage information in Infrastore, a scalable read-only data store with an interactive SQL-like interface via Dremel [61]. This data is used for usage-based charging, debugging job and system failures, and long-term capacity planning. It also provided the data for the Google cluster workload trace [80].
Borg将所有的作业提交、任务事件、以及每个任务的详细资源使用都记录在Infrastore里。Infrastore是一个可扩展的只读数据存储,通过Dremel[61]提供了类似SQL的交互式接口。这些数据用以支持基于使用量的收费,调试作业和系统故障,以及长期容量规划。公开的Google集群负载数据集[80]也来自于这些数据。
All of these features help users to understand and debug the behavior of Borg and their jobs, and help our SREs manage a few tens of thousands of machines per person.
所有这些特性帮助用户理解和调试Borg及其作业的行为,并帮助我们的SRE实现每人管理超过上万台机器。
3. Borg架构
A Borg cell consists of a set of machines, a logically centralized controller called the Borgmaster, and an agent process called the Borglet that runs on each machine in a cell (see Figure 1). All components of Borg are written in C++.
一个Borg的Cell包括一组机器,一个逻辑上集中的控制器,称为Borgmaster,以及运行在每台机器上的称为Borglet的代理进程(见图1)。Borg的组件都是用C++实现的。
3.1 Borgmaster
Each cell’s Borgmaster consists of two processes: the main Borgmaster process and a separate scheduler (§3.2). The main Borgmaster process handles client RPCs that either mutate state (e.g., create job) or provide read-only access to data (e.g., lookup job). It also manages state machines for all of the objects in the system (machines, tasks, allocs, etc.), communicates with the Borglets, and offers a web UI as a backup to Sigma.
Cell的Borgmaster由两个进程组成:Borgmaster主进程和一个单独的调度进程(§3.2)。Borgmaster主进程处理客户端的RPC,包括修改状态(如创建作业),或提供只读数据(如查找作业)。它还管理着系统中所有对象(机器、任务、Allocs等)的状态,与Borglet通信,并提供一个Web UI(作为Sigma的备份)。
The Borgmaster is logically a single process but is actually replicated five times. Each replica maintains an inmemory copy of most of the state of the cell, and this state is also recorded in a highly-available, distributed, Paxos-based store [55] on the replicas’ local disks. A single elected master per cell serves both as the Paxos leader and the state mutator, handling all operations that change the cell’s state, such as submitting a job or terminating a task on a machine. A master is elected (using Paxos) when the cell is brought up and whenever the elected master fails; it acquires a Chubby lock so other systems can find it. Electing a master and failing-over to the new one typically takes about 10 s, but can take up to a minute in a big cell because some in-memory state has to be reconstructed. When a replica recovers from an outage, it dynamically re-synchronizes its state from other Paxos replicas that are up-to-date.
Borgmaster在逻辑上是单个进程,但实际上有5个副本。每个副本在内存维护着Cell状态的拷贝,该状态同时保存在由这些副本的本地硬盘组成的一个基于Paxos[55]的高可用、分布式存储上。每个Cell中仅有一个选举出来的Master,它同时作为Paxos的Leader和状态修改者,处理所有变更Cell状态的请求,例如提交作业或者结束某台机器上的一个任务。当Cell启动或者上一个Master故障时,新的Master会通过Paxos算法选举出来;新Master会获取一个Chubby锁,这样其它的系统就可以找到它。选举并转移到新的Master通常需要10秒,但在大的Cell里可能需要长达1分钟,因为需要重构一些内存状态。当一个副本从宕机恢复后,它会动态地从其它最新的Paxos副本中重新同步自己的状态。
The Borgmaster’s state at a point in time is called a checkpoint, and takes the form of a periodic snapshot plus a change log kept in the Paxos store. Checkpoints have many uses, including restoring a Borgmaster’s state to an arbitrary point in the past (e.g., just before accepting a request that triggered a software defect in Borg so it can be debugged); fixing it by hand in extremis; building a persistent log of events for future queries; and offline simulations.
某个时刻的Borgmaster状态被称为检查点(Checkpoint),以定期快照加变更日志的形式保存在Paxos存储里。检查点有很多用途:如重建过去任意时刻的Borgmaster状态(例如,在接收一个触发了Borg故障的请求之前的时刻,这样就可以用来调试);特别情况下可以手工修复检查点;构建一个持久的事件日志供日后查询;或用于离线仿真。
A high-fidelity Borgmaster simulator called Fauxmaster can be used to read checkpoint files, and contains a complete copy of the production Borgmaster code, with stubbed-out interfaces to the Borglets. It accepts RPCs to make state machine changes and perform operations, such as “schedule all pending tasks”, and we use it to debug failures, by interacting with it as if it were a live Borgmaster, with simulated Borglets replaying real interactions from the checkpoint file. A user can step through and observe the changes to the system state that actually occurred in the past. Fauxmaster is also useful for capacity planning (“how many new jobs of this type would fit?”), as well as sanity checks before making a change to a cell’s configuration (“will this change evict any important jobs?”).
一个高保真的Borgmaster模拟器,称为Fauxmaster,可以读取检查点文件。Fauxmaster的代码拷贝自线上的Borgmaster,还有对Borglet的存根接口。它接收RPC来改变状态,执行操作,例如“调度所有等待的任务”。我们用它来调试故障,像跟在线的Borgmaster那样与模拟器交互,用模拟的Borglet重放检查点文件里的真实交互。用户可以单步执行并观察系统过去确实发生了的状态变化。Fauxmaster也用于容量规划(可以接收多少个此类型的作业?),以及在实际更改Cell配置前做可行性检查(这个变更会导致关键作业异常退出吗?)
3.2 调度 scheduler
When a job is submitted, the Borgmaster records it persistently in the Paxos store and adds the job’s tasks to the pending queue. This is scanned asynchronously by the scheduler, which assigns tasks to machines if there are sufficient available resources that meet the job’s constraints. (The scheduler primarily operates on tasks, not jobs.) The scan proceeds from high to low priority, modulated by a round-robin scheme within a priority to ensure fairness across users and avoid head-of-line blocking behind a large job. The scheduling algorithm has two parts: feasibility checking, to find machines on which the task could run, and scoring, which picks one of the feasible machines.
当提交一个作业后,Borgmaster会把它保存在持久的Paxos存储上,并将这个作业的所有任务加入等待队列中。调度器异步地扫描等待队列,将任务分配到满足作业约束且有足够资源的机器上(调度器主要操作Task,而不是Job)。队列扫描从高优先级到低优先级,同优先级则按user轮询task,这可以避免大型作业产生一堆task造成的线端堵塞。调度算法有两个部分:可行性检查,找到一组可以运行任务的机器;评分,从中选择一个合适的机器。
In feasibility checking, the scheduler finds a set of machines that meet the task’s constraints and also have enough “available” resources – which includes resources assigned to lower-priority tasks that can be evicted. In scoring, the scheduler determines the “goodness” of each feasible machine. The score takes into account user-specified preferences, but is mostly driven by built-in criteria such as minimizing the number and priority of preempted tasks, picking machines that already have a copy of the task’s packages, spreading tasks across power and failure domains, and packing quality including putting a mix of high and low priority tasks onto a single machine to allow the high-priority ones to expand in a load spike.
在可行性检查阶段,调度器会找到一组满足任务约束且有足够可用资源的机器—可用资源包括已经分配给低优先级任务但可以抢占的资源。在评分阶段,调度器确定每台可行机器的适宜性。评分考虑了用户特定的偏好,但主要取决于内建的标准:例如最小化被抢占任务的个数和优先级,选择已经有该任务安装包的机器,尽可能使任务分散在不同的供电和故障域,以及装箱(Packing)质量(在单台机器上混合高、低优先级的任务,以允许高优先级任务在负载尖峰扩容)等。
Borg originally used a variant of E-PVM[4] for scoring, which generates a single cost value across heterogeneous resources and minimizes the change in cost when placing a task. In practice, E-PVM ends up spreading load across all the machines, leaving headroom for load spikes – but at the expense of increased fragmentation, especially for large tasks that need most of the machine; we sometimes call this “worst fit”.
Borg早期使用修改过的E-PVM[4]算法来评分。这个算法对异构的资源生成了唯一成本值,放置任务的目标是使成本的变化量最小。在实践中,E-PVM会把负载分散到所有机器,为负载尖峰预留出资源 —— 这样的代价是增加了碎片,特别是对需要占据机器大部分资源的大型任务而言;我们有时称其为“最差匹配”。
The opposite end of the spectrum is “best fit”, which tries to fill machines as tightly as possible. This leaves some machines empty of user jobs (they still run storage servers), so placing large tasks is straightforward, but the tight packing penalizes any mis-estimations in resource requirements by users or Borg. This hurts applications with bursty loads, and is particularly bad for batch jobs which specify low CPU needs so they can schedule easily and try to run opportunistically in unused resources: 20% of non-prod tasks request less than 0.1 CPU cores.
与之相反的是“最佳匹配”,把机器上的任务塞的越满越好。这就“空”出一些没有用户作业的机器(它们仍运行存储服务),这样放置大型任务就比较直接了。但是,如果用户或Borg错误估计了资源需求,紧实的装箱会对此造成(性能上的)惩罚。这种策略不利于有突发负载的应用,而且对申请少量CPU的批处理作业特别不友好,这些作业申请少量CPU本来是为了更容易被调度执行,并抓住机会使用空闲资源:20%的non-prod 任务申请少于0.1个CPU核。
Our current scoring model is a hybrid one that tries to reduce the amount of stranded resources – ones that cannot be used because another resource on the machine is fully allocated. It provides about 3–5% better packing efficiency (defined in [78]) than best fit for our workloads.
我们目前的评分模型是混合的,试图减少搁浅(Stranded)的资源(指一台机器因某些类型资源全部分配了,导致未能分配的其它类型资源)。对我们的负载而言,这个模型比“最佳匹配”提升了3%-5%的装箱效率(以[78]定义的方式评价)。
If the machine selected by the scoring phase doesn’t have enough available resources to fit the new task, Borg preempts(kills) lower-priority tasks, from lowest to highest priority, until it does. We add the preempted tasks to the scheduler’s pending queue, rather than migrate or hibernate them.
如果评分后选中的一台机器没有足够的资源来运行新任务,Borg会抢占低优先级的任务,从最低优先级向上逐级抢占,直到资源足够运行该任务。被抢占的任务放回到调度器的等待队列里,而不是被迁移或休眠(注:例外情况是,为Google Compute Engine提供虚拟机的任务会被迁移)。
Task startup latency (the time from job submission to a task running) is an area that has received and continues to receive significant attention. It is highly variable, with the median typically about 25 s. Package installation takes about 80% of the total: one of the known bottlenecks is contention for the local disk where packages are written to. To reduce task startup time, the scheduler prefers to assign tasks to machines that already have the necessary packages (programs and data) installed: most packages are immutable and so can be shared and cached. (This is the only form of data locality supported by the Borg scheduler.) In addition, Borg distributes packages to machines in parallel using tree-and torrent-like protocols.
任务的启动延迟(从提交作业到任务开始运行之间的时间段)是我们持续重点关注的。这个时间差别很大,中位数约25秒。安装软件包耗费了其中80%的时间:一个已知的瓶颈就是软件包写入时对本地硬盘的竞争。为了减少任务启动时间,调度器偏好将任务分配到已经有必需的软件包(程序及数据)的机器(和打散率是冲突的):大部分包是只读的,所以可以被共享和缓存(这是Borg调度器唯一支持的本地数据使用形式)。另外,Borg通过树形和类似BT的协议并发地将软件包分发到多个机器上。
Additionally, the scheduler uses several techniques to let it scale up to cells with tens of thousands of machines (§3.4).
此外,调度器采用多种技术使其能够扩展到数万台机器的Cell(§3.4)。
3.3 Borglet
The Borglet is a local Borg agent that is present on every machine in a cell. It starts and stops tasks; restarts them if they fail; manages local resources by manipulating OS kernel settings; rolls over debug logs; and reports the state of the machine to the Borgmaster and other monitoring systems.
Borglet是部署在Cell每台机器上的本机Borg代理。它负责启动和停止任务;重启失败的任务;通过OS内核设置来管理本地资源;切割debug日志;把本机的状态上报给Borgmaster和其它监控系统。
The Borgmaster polls each Borglet every few seconds to retrieve the machine’s current state and send it any outstanding requests. This gives Borgmaster control over the rate of communication, avoids the need for an explicit flow control mechanism, and prevents recovery storms [9].
Borgmaster每过几秒就会轮询每个Borglet来获取机器的当前状态,并向其发送请求。这让Borgmaster能控制通信频率,省去了显式的流量控制机制,而且防止了恢复风暴[9]。 (只有轮询拉模式,也即fall over和恢复最快快不过这个拉取interval。)
The elected master is responsible for preparing messages to send to the Borglets and for updating the cell’s state with their responses. For performance scalability, each Borgmaster replica runs a stateless link shard to handle the communication with some of the Borglets; the partitioning is recalculated whenever a Borgmaster election occurs. For resiliency, the Borglet always reports its full state, but the link shards aggregate and compress this information by reporting only differences to the state machines, to reduce the update load at the elected master.
选举出来的Master负责准备发送给Borglet的消息,并根据Borglet的响应更新Cell的状态。为使性能可扩展,每个Borgmaster副本会负责一个无状态的链接分片(Link Shard)来处理部分Borglet的通信;Borgmaster选举后分片会重新计算。(Borgmaster通常5副本,即使把轮训任务分给replia来做 可扩展性也不怎么样) 为了保证容错(Resiliency),Borglet总是汇报全部状态(每次都是全量汇报),但是Link Shard只汇报变化值,从而聚合、压缩这些信息,减少Master更新的负担。
If a Borglet does not respond to several poll messages its machine is marked as down and any tasks it was running are rescheduled on other machines. If communication is restored the Borgmaster tells the Borglet to kill those tasks that have been rescheduled, to avoid duplicates. A Borglet continues normal operation even if it loses contact with the Borgmaster, so currently-running tasks and services stay up even if all Borgmaster replicas fail.
如果某个Borglet几次没有响应轮询请求,该机器会被标记为宕机,其上运行的所有任务会被重新调度到其它机器。如果通讯恢复了,Borgmaster会让这个Borglet杀掉已经被重新调度出去的任务,以避免重复。即便无法与Borgmaster通信,Borglet仍会继续正常运行。所以即使所有的Borgmaster都出故障了,正在运行的任务和服务还会保持运行。 (当Borglet失联,其上的task就是未知状态的了,也许都死了,也许还活着。如果想保证exactly once语义单靠Borg是做不到的,得task自己搞;not more then once看起来Borg也是不支持的,它只支持at least once)
3.4 扩展性 Scalability
We are not sure where the ultimate scalability limit to Borg’s centralized architecture will come from; so far, every time we have approached a limit, we’ve managed to eliminate it. A single Borgmaster can manage many thousands of machines in a cell, and several cells have arrival rates above 10000 tasks per minute. A busy Borgmaster uses 10–14 CPU cores and up to 50 GiB RAM. We use several techniques to achieve this scale.
我们还没有遇到Borg这种集中式架构的终极扩展上限。我们顺利地突破了遇到的每个限制。一个单独的Borgmaster可以管理有数千台机器的Cell,有些Cell每分钟有10000多个任务到达。一个繁忙的Borgmaster使用10~14个CPU核以及50GB内存。我们用了几项技术来实现这种扩展性。
Early versions of Borgmaster had a simple, synchronous loop that accepted requests, scheduled tasks, and communicated with Borglets. To handle larger cells, we split the scheduler into a separate process so it could operate in parallel with the other Borgmaster functions that are replicated for failure tolerance. A scheduler replica operates on a cached copy of the cell state. It repeatedly: retrieves state changes from the elected master (including both assigned and pending work); updates its local copy; does a scheduling pass to assign tasks; and informs the elected master of those assignments. The master will accept and apply these assignments unless they are inappropriate (e.g., based on out of date state), which will cause them to be reconsidered in the scheduler’s next pass. This is quite similar in spirit to the optimistic concurrency control used in Omega [69], and indeed we recently added the ability for Borg to use different schedulers for different workload types.
早期版本的Borgmaster使用一个简单的,同步的循环来处理请求、调度任务,并与Borglet通信。为了处理更大的Cell,我们把调度器分离为一个单独的进程,这样它就可以与其它的Borgmaster功能并行执行,而这些其它的功能有多副本以便容错。调度器使用一份缓存的Cell状态拷贝,重复执行下面的操作:从选举出来的Master获取状态变更(包括已分配的和等待中的工作);更新自己的本地拷贝;执行一轮调度来分配任务;将分配信息发送给Master。Master会接受并应用这些分配,但如果分配不适合(例如,是基于过时的状态做出的),就会等待调度器的下一轮调度。这与Omega [69]使用的乐观并发控制思路很相似,而且我们最近还给Borg添加了对 不同负载类型使用不同调度器的功能。
(从最后一句看起来,是有多个scheduler进程了?它怎么做fail over–和BorgMaster进程保活?而且工作做到一半,调度已经执行了但还没上报master就死了怎么算?)
To improve response times, we added separate threads to talk to the Borglets and respond to read-only RPCs. For greater performance, we sharded (partitioned) these functions across the five Borgmaster replicas §3.3. Together, these keep the 99%ile response time of the UI below 1s and the 95%ile of the Borglet polling interval below 10 s.
为了改进响应时间,Borglet使用独立的线程分别进行通信和响应只读RPC。为了更好的性能,我们将这些请求划分给5个Borgmaster副本(§3.3)。总的效果是,UI响应时间的99%分位数小于1秒,而Borglet轮询间隔的95%分位数小于10秒。
Several things make the Borg scheduler more scalable: 一些提高Borg调度器扩展性的方法如下:
Score caching: Evaluating feasibility and scoring a machine is expensive, so Borg caches the scores until the properties of the machine or task change – e.g., a task on the machine terminates, an attribute is altered, or a task’s requirements change. Ignoring small changes in resource quantities reduces cache invalidations.
缓存评分:计算一台机器的可行性和评分是比较昂贵的,所以Borg会一直缓存评分,直到这台机器或者任务的属性发生了变化 —— 例如,这台机器上的某个任务结束了,一些属性修改了,或者任务的需求改变了。忽略小额的资源变化可以减少缓存失效。 (打分是scheduler的责任,这些资源变化是BorgMaster收集上来的,然后scheduler全量把cache拉过来的吧(这个做增量觉得不可行),然后是做全量diff计算-》找到变化了的-》更新,酱?)
Equivalence classes: Tasks in a Borg job usually have identical requirements and constraints, so rather than determining feasibility for every pending task on every machine, and scoring all the feasible machines, Borg only does feasibility and scoring for one task per equivalence class – a group of tasks with identical requirements.
等效类:一组有相同要求的tasks互为等效类。一般来说,同一个Borg 作业的任务有相同的请求和约束。任务等效类即一组有相同需求的任务。Borg只对等效类中的一个任务进行可行性检查和评分,而不是对等待的每个任务去检查一遍所有机器的可行性并对可行的机器评分。
Relaxed randomization: It is wasteful to calculate feasibility and scores for all the machines in a large cell, so the scheduler examines machines in a random order until it has found “enough” feasible machines to score, and then selects the best within that set. This reduces the amount of scoring and cache invalidations needed when tasks enter and leave the system, and speeds up assignment of tasks to machines. Relaxed randomization is somewhat akin to the batch sampling of Sparrow [65] while also handling priorities, preemptions, heterogeneity and the costs of package installation.
适度随机:在一个大的Cell中,对所有机器都去计算一遍可行性和评分是很浪费的。调度器会随机地检查机器,直到找到足够多的可用机器来评分,然后从中挑选出最好的一个。这减少了任务启动和退出所需的评分次数及导致的缓存失效,加快了任务分配过程。适度随机有点类似Sparrow[65]的批量采样技术(Sparrow的批量采样考虑的是机器上的任务队列长度),但Borg还处理了优先级、抢占、异构性和安装软件包的成本。
In our experiments (§5), scheduling a cell’s entire workload from scratch typically took a few hundred seconds, but did not finish after more than 3 days when the above techniques were disabled. Normally, though, an online scheduling pass over the pending queue completes in less than half a second.
在我们的实验中(§5),从零开始调度整个Cell的工作负载只要几百秒,但禁用上面几项技术的话,3天都不够。正常情况下,半秒之内就能完成一遍等待队列的在线调度。
4. 可用性 Availability

图3. 生产环境任务和非生产环境任务的异常退出率及原因(包括抢占、资源不足、机器故障、机器关机、其它)。数据从2013-08-01开始。
Failures are the norm in large scale systems [10, 11, 22]. Figure 3 provides a breakdown of task eviction causes in 15 sample cells. Applications that run on Borg are expected to handle such events, using techniques such as replication, storing persistent state in a distributed file system, and (if appropriate) taking occasional checkpoints. Even so, we try to mitigate the impact of these events. For example, Borg:
大型系统里故障是很常见的[10, 11, 12]。图3展示了在15个样本Cell里任务异常退出的原因分类。在Borg上运行的应用需要能处理这种事件,可采用的技术有多副本、保存持久状态到分布式存储,或定期快照(如果可行的话)等。当然,我们也尽可能的缓解异常事件的影响。例如,Borg提供了:
- 自动重新调度异常退出的任务,如果必要,可以放置到另一台机器上去运行。automatically reschedules evicted tasks, on a new machine if necessary;
- 把一个作业的任务分散到不同的可用域,例如机器、机架、供电域层次,以减少关联失效。reduces correlated failures by spreading tasks of a job across failure domains such as machines, racks, and power domains;
- 在机器/OS升级等维护活动期间,限制任务受影响的速率,以及同一作业中同时中止的任务的个数。limits the allowed rate of task disruptions and the number of tasks from a job that can be simultaneously down during maintenance activities such as OS or machine upgrades;
- 使用声明式的预期状态表示,及幂等的变更操作,这样故障的客户端可以无损地重复提交故障期间漏掉的请求。uses declarative desired-state representations and idempotent mutating operations, so that a failed client can harmlessly resubmit any forgotten requests;
- 对于失联的机器上的任务,限制重新调度的速率,因为大规模的机器故障和网络分区是很难区分的。rate-limits finding new places for tasks from machines that become unreachable, because it cannot distinguish between large-scale machine failure and a network partition;
- 回避重复调度曾造成过任务或机器崩溃的 任务::机器 对。avoids repeating task::machine pairings that cause task or machine crashes;
- 通过不断重新执行日志保存任务来恢复写入本地硬盘的关键中间数据(§2.4),就算这个日志关联的Alloc已经终止或调度到其它机器上了。用户可以设置系统持续重复尝试多久,通常是几天时间。recovers critical intermediate data written to local disk by repeatedly re-running a logsaver task (§2.4), even if the alloc it was attached to is terminated or moved to another machine. Users can set how long the system keeps trying; a few days is common.
A key design feature in Borg is that already-running tasks continue to run even if the Borgmaster or a task’s Borglet goes down. But keeping the master up is still important because when it is down new jobs cannot be submitted or existing ones updated, and tasks from failed machines cannot be rescheduled.
Borg的一个关键设计特性是:就算Borgmaster或者Borglet宕掉了,已经运行的任务还会继续运行下去。不过,保持Master正常运行仍然重要,因为在它退出后就无法提交新的作业,无法更新运行作业的状态,也不能重新调度故障机器上的任务。
Borgmaster uses a combination of techniques that enable it to achieve 99.99% availability in practice: replication for machine failures; admission control to avoid overload; and deploying instances using simple, low-level tools to minimize external dependencies. Each cell is independent of the others to minimize the chance of correlated operator errors and failure propagation. These goals, not scalability limitations, are the primary argument against larger cells.
Borgmaster使用多项的技术支持其获得99.99%的实际可用性:多副本应对机器故障;准入控制应对过载;使用简单、底层的工具部署实例,以减少外部依赖。Cell彼此是独立的,减少了关联误操作和故障传播的机会。同时这也是我们不扩大Cell规模的主要考虑,而并非是受限于扩展性。
5. 利用率 Utilization
One of Borg’s primary goals is to make efficient use of Google’s fleet of machines, which represents a significant financial investment: increasing utilization by a few percentage points can save millions of dollars. This section discusses and evaluates some of the policies and techniques that Borg uses to do so.
Borg的一个主要目标就是有效地利用Google的大量机器(这是一大笔财务投资):让效率提升几个百分点就能省下几百万美元。这一节讨论和评估了一些Borg使用的策略和技术。
5.1 评估方法论 Evaluation methodology
Our jobs have placement constraints and need to handle rare workload spikes, our machines are heterogenous, and we run batch jobs in resources reclaimed from service jobs. So, to evaluate our policy choices we needed a more sophisticated metric than “average utilization”. After much experimentation we picked cell compaction: given a workload, we found out how small a cell it could be fitted into by removing machines until the workload no longer fitted, repeatedly re-packing the workload from scratch to ensure that we didn’t get hung up on an unlucky configuration. This provided clean termination conditions and facilitated automated comparisons without the pitfalls of synthetic workload generation and modeling [31]. A quantitative comparison of evaluation techniques can be found in [78]: the details are surprisingly subtle.
作业有部署约束,而且需要处理负载尖峰(尽管比较少见),机器是异构的,我们用从服务型作业回收的资源来运行批处理作业。因此,我们需要一个比“平均利用率”更高级的指标来评估我们的策略选择。大量实验后,我们选择了Cell压缩量(cell Compaction):给定一个负载,我们不断地移除机器,直到cell无法容纳该负载为止,从而得知运行该负载所需的最小Cell规模。从空集群开始部署该负载并重复多次,以减少特殊情况的影响。终止条件是明确的,对比可以自动化,避免了生成和建模合成负载的陷阱[31]。[78]提供了评估技术的定量比较,其中的细节非常微妙。
It wasn’t possible to perform experiments on live production cells, but we used Fauxmaster to obtain high-fidelity simulation results, using data from real production cells and workloads, including all their constraints, actual limits, reservations, and usage data (§5.5). This data came from Borg checkpoints taken on Wednesday 2014-10-01 14:00 PDT. (Other checkpoints produced similar results.) We picked 15 Borg cells to report on by first eliminating special-purpose, test, and small (< 5000 machines) cells, and then sampled the remaining population to achieve a roughly even spread across the range of sizes.
我们不可能在线上Cell进行实验,但是我们用了Fauxmaster来获得高保真的模拟效果,它使用了真实生产Cell和负载的数据,包括所有约束、实际限制、预留和使用量数据(§5.5)。实验数据提取自2014-10-01 14:00 PDT的Borg快照(其它快照也有类似的结论)。我们首先排除了特殊用途的、测试用的、小型的(少于5000台机器)的Cell,然后从剩下的Cell中选取了15个样本,尽量各种size的cell都抽样到。
To maintain machine heterogeneity in the compacted cell we randomly selected machines to remove. To maintain workload heterogeneity, we kept it all, except for server and storage tasks tied to a particular machine (e.g., the Borglets). We changed hard constraints to soft ones for jobs larger than half the original cell size, and allowed up to 0.2% tasks to go pending if they were very “picky” and could only be placed on a handful of machines; extensive experiments showed that this produced repeatable results with low variance. If we needed a larger cell than the original we cloned the original cell a few times before compaction; if we needed more cells, we just cloned the original.
为了保持机器异构性,在Cell压缩实验中,我们随机地移除机器。为了保持工作负载的异构性,我们保留了所有负载(除了那些绑定到特定机器的服务和存储任务,如Borglet)。我们把那些需要超过原Cell大小一半的作业的硬性限制改成柔性的,允许不超过0.2%的任务一直等待,这是针对一些特别“挑剔”的,只能放置在很少的特定机器上的任务;充分的实验表明结果是可复现的,波动很小。如果需要一个大型的Cell,就把原Cell复制几倍;如果需要更多的Cell,也是复制原Cell。
Each experiment was repeated 11 times for each cell with different random-number seeds. In the graphs, we use an error bar to display the min and max of the number of machines needed, and select the 90%ile value as the “result” – the mean or median would not reflect what a system administrator would do if they wanted to be reasonably sure that the workload would fit. We believe cell compaction provides a fair, consistent way to compare scheduling policies, and it translates directly into a cost/benefit result: better policies require fewer machines to run the same workload.
每个实验都用不同的随机数种子对每个Cell重复了11次。图中,我们用误差线线来表示所需机器数量的最大和最小值,选择90%分位数作为结果 —— 平均值或中位数不能反映系统管理员所期望的充分把握。我们认为Cell压缩率是一个公平一致的比较调度策略的方法,而且可以直接转化为成本/收益的结果:更好的策略只需要更少的机器来运行相同的负载。(这才是合理指标制定过程。本质就是为了省机器,那就直接制定个直接相关指标,不搞间接指标。哪怕这个指标不容易获得)
Our experiments focused on scheduling (packing) a workload from a point in time, rather than replaying a long-term workload trace. This was partly to avoid the difficulties of coping with open and closed queueing models [71, 79], partly because traditional time-to-completion metrics don’t apply to our environment with its long-running services, partly to provide clean signals for making comparisons, partly because we don’t believe the results would be significantly different, and partly a practical matter: we found ourselves consuming 200 000 Borg CPU cores for our experiments at one point—even at Google’s scale, this is a non-trivial investment.
我们的实验关注于即时的调度(装箱),而不是重放一段长时间的负载记录。部分原因是避免处理开放或闭合的队列模型[71, 79]的困难;部分是传统的完成时间不适用于长时间运行的服务;部分是这样可以提供明确的比较结果;部分是因为我们认为不会对结果产生显著影响;还有部分现实原因,我们发现一次实验使用了20万个Borg CPU核 —— 即便对Google而言,这个成本也不是个小数目。
In production, we deliberately leave significant headroom for workload growth, occasional “black swan” events, load spikes, machine failures, hardware upgrades, and large-scale partial failures (e.g., a power supply bus duct). Figure 4 shows how much smaller our real-world cells would be if we were to apply cell compaction to them. The baselines in the graphs that follow use these compacted sizes.
生产环境中,我们特意保留了一些裕度(Headroom),以应对负载增长、偶然的“黑天鹅”事件、负载尖峰、机器故障、硬件升级、以及大范围的局部故障(如供电母线短路)。图4显示了如果应用Cell压缩,实际的Cell可以压缩到多小。下文的图使用这些压缩后的大小作为基准值。
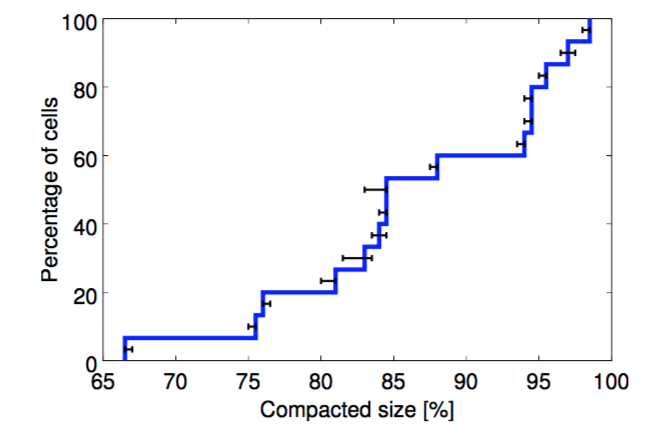
Figure 4: The effects of compaction. A CDF of the percentage of original cell size achieved after compaction, across 15 cells. 图4. 压缩的效果。15个Cell在压缩后相比原规模的百分比累积分布(CDF Cumulative Distribution Function:F(a)=P(x<=a))
5.2 Cell共享 Cell sharing
Nearly all of our machines run both prod and non-prod tasks at the same time: 98% of the machines in shared Borg cells, 83% across the entire set of machines managed by Borg. (We have a few dedicated cells for special uses.)
几乎所有的机器都同时运行prod和non-prod的任务:在共享的Cell里是98%的机器,在所有Borg管理的机器里是83%(有一些是Cell专用的)。
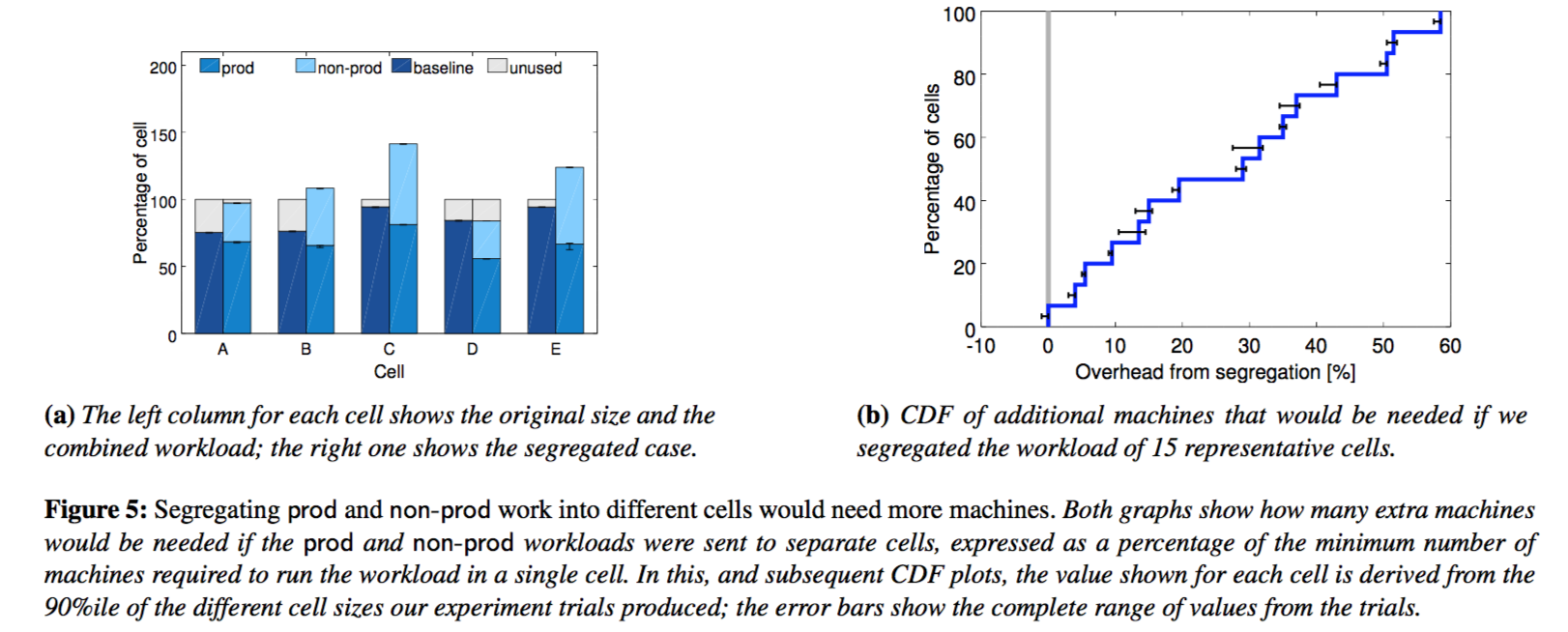
图5. 将prod和non-prod工作划分到不同的集群将需要更多的机器。两幅图中的百分比都是相对于单个集群所需机器的最少数量而言的
Since many other organizations run user-facing and batch jobs in separate clusters, we examined what would happen if we did the same. Figure 5 shows that segregating prod and non-prod work would need 20–30% more machines in the median cell to run our workload. That’s because prod jobs usually reserve resources to handle rare workload spikes, but don’t use these resources most of the time. Borg reclaims the unused resources (§5.5) to run much of the non-prod work, so we need fewer machines overall.
鉴于很多外部组织将面向用户的作业和批处理作业分别运行在不同的集群上,我们检查一下如果我们也这么做会怎样。图5表明,在一个中等大小的Cell上,分开运行prod和non-prod的工作负载将需要增加20-30%的机器。这是因为prod的作业通常会保留一些资源来应对极少发生的负载尖峰,但大多情况下用不到这些资源。Borg回收了这些用不到的资源(§5.5),来运行non-prod的工作,所以总体我们只需要更少的机器。
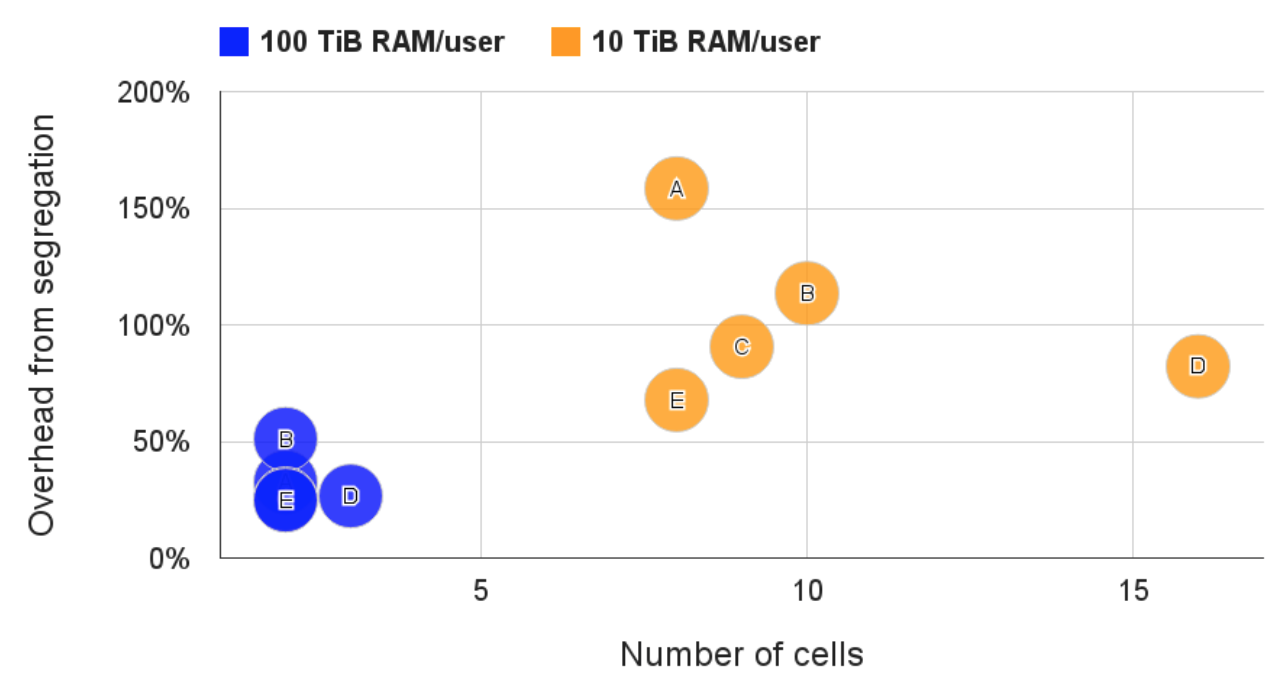
Figure 6: Segregating users would need more machines. The total number of cells and the additional machines that would be needed if users larger than the threshold shown were given their own private cells, for 5 different cells. 图6. 将用户分开到不同的集群也会需要更多的机器
Most Borg cells are shared by thousands of users. Figure 6 shows why. For this test, we split off a user’s workload into a new cell if they consumed at least 10 TiB of memory (or 100 TiB). Our existing policy looks good: even with the larger threshold, we would need 2–16⇥ as many cells, and 20–150% additional machines. Once again, pooling resources significantly reduces costs.
大部分Borg Cell被数千个用户共享使用。图6展示了为什么要共享。测试中,如果一个用户消费了超过10TiB(或100TiB)的内存,我们就把这个用户的工作负载分离到另一个Cell中。我们目前的共享策略是有效的:即使100TiB的阈值,也需要2-16倍的Cell,增加20-150%的机器。将资源池化再次显著地节省了成本。
But perhaps packing unrelated users and job types onto the same machines results in CPU interference, and so we would need more machines to compensate? To assess this, we looked at how the CPI (cycles per instruction) changed for tasks in different environments running on the same machine type with the same clock speed. Under these conditions, CPI values are comparable and can be used as a proxy for performance interference, since a doubling of CPI doubles the runtime of a CPU-bound program. The data was gathered from ⇠ 12000 randomly selected prod tasks over a week, counting cycles and instructions over a 5 minute interval using the hardware profiling infrastructure described in [83], and weighting samples so that every second of CPU time is counted equally. The results were not clear-cut.
但是,把很多不相关的用户和作业类型放置到同一台机器上可能会造成CPU冲突(?是说频繁切换上下文造成cpu利用率低么??),我们是否需要更多的机器来补偿?为评估这一点,我们看一下固定机器类型和时钟频率,任务的CPI(Cycles per Instruction,执行每条指令平均所需时钟数,越大则程序执行越慢)在其它环境条件不同的影响下是如何变化的。在这种实验条件下,CPI是一个可比较的指标,而且可以表征性能冲突,因为2倍的CPI意味着一个CPU密集型程序需要2倍的执行时间。数据是在一周内从约12000个随机选择的prod任务获取的,使用了[83]中介绍的硬件剖析工具记录5分钟内的时钟数和指令数,并调整了采样的权重,使CPU时间的每秒都均等处理。结果并非直截了当的:
(1) We found that CPI was positively correlated with two measurements over the same time interval: the overall CPU usage on the machine, and (largely independently) the number of tasks on the machine; adding a task to a machine increases the CPI of other tasks by 0.3% (using a linear model fitted to the data); increasing machine CPU usage by 10% increases CPI by less than 2%. But even though the correlations are statistically significant, they only explain 5% of the variance we saw in CPI measurements; other factors dominate, such as inherent differences in applications and specific interference patterns [24, 83].
(1)我们发现CPI在同一个时间段内和下面两个量正相关:这台机器上总的CPU使用量,以及这个机器上同时运行的任务个数(基本上独立);每向一台机器上增加一个任务,就会使其它任务的CPI增加0.3%(从数据拟合的线性模型给出的预测值);将一台机器的CPU使用量增加10%,就会增加将近2%的CPI。尽管相关性在统计意义上是显著的,也只是解释了CPI变化的5%。还有其它的因素,支配着CPI的变化,例如,应用程序固有的差别,以及特殊的干扰模式[24, 83]。
(2) Comparing the CPIs we sampled from shared cells to ones from a few dedicated cells with less diverse applications, we saw a mean CPI of 1.58 (s = 0.35) in shared cells and a mean of 1.53 (s = 0.32) in dedicated cells – i.e., CPU performance is about 3% worse in shared cells.
(2)比较从共享Cell和只运行几种应用的少数专用Cell获取的CPI采样,我们看到共享Cell里的CPI平均值为1.58(σ=0.35,标准差),专用Cell的CPI平均值是1.53(σ=0.32) —— 也就是说,共享Cell的性能差3%。
(3) To address the concern that applications in different cells might have different workloads, or even suffer selection bias (maybe programs that are more sensitive to interference had been moved to dedicated cells), we looked at the CPI of the Borglet, which runs on all the machines in both types of cell. We found it had a CPI of 1.20 (s = 0.29) in dedicated cells and 1.43 (s = 0.45) in shared ones, suggesting that it runs 1.19⇥ as fast in a dedicated cell as in a shared one, although this over-weights the effect of lightly loaded machines, slightly biasing the result in favor of dedicated cells.
(3)不同Cell的应用会有不同的工作负载,甚至会有幸存者偏差(或许对冲突更敏感的程序会被挪到专用Cell里面去),为了消除上述顾虑,我们观察了Borglet的CPI,它运行在所有Cell的所有机器上。我们发现专用Cell里Borlet的CPI平均值是1.20(σ=0.29),而共享Cell里的CPI平均值为1.43(σ=0.45),表明在专用Cell上比在共享Cell上快1.19倍,不过这个结果忽略了专用Cell中的机器负载较轻的因素,即稍偏向专用Cell。
These experiments confirm that performance comparisons at warehouse-scale are tricky, reinforcing the observations in [51], and also suggest that sharing doesn’t drastically increase the cost of running programs.
这些实验表明了仓库级别的性能比较是复杂的,强化了[51]中的观察,但也说明共享并没有显著增加运行程序的开销。
But even assuming the least-favorable of our results, sharing is still a win: the CPU slowdown is outweighed by the decrease in machines required over several different partitioning schemes, and the sharing advantages apply to all resources including memory and disk, not just CPU.
不过,就算从结果中最差的数据来看,共享还是有益的:比起CPU的降速,共享比各个划分方案都减少了机器,这一点更重要,而且共享的收益适用于包括内存和硬盘等各种资源,不仅仅是CPU。
5.3 大型Cell
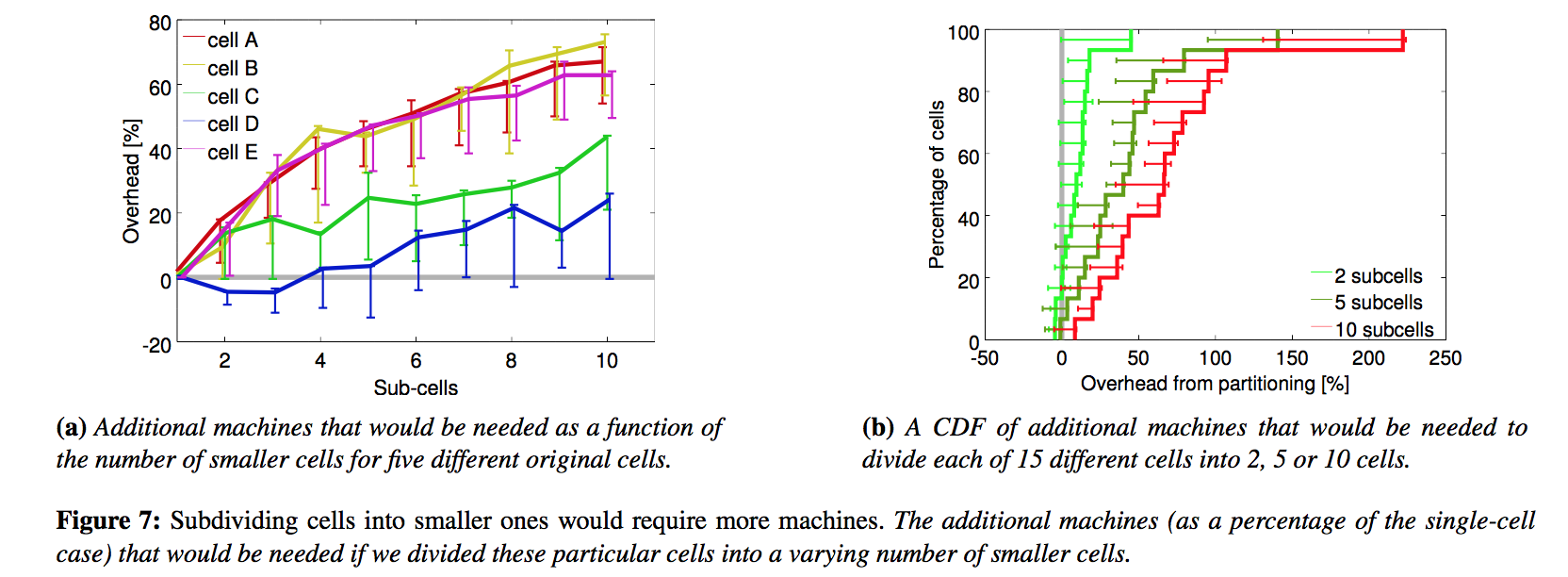
图7. 将Cell分成更小的规模将需要更多的机器
Google builds large cells, both to allow large computations to be run, and to decrease resource fragmentation. We tested the effects of the latter by partitioning the workload for a cell across multiple smaller cells – by first randomly permuting the jobs and then assigning them in a round-robin manner among the partitions. Figure 7 confirms that using smaller cells would require significantly more machines.
Google建立了大型Cell,一是为了允许运行大型任务,二是为了减少资源碎片。为测试减少碎片的效果,我们把负载从一个Cell分散多个较小的Cell中 —— 首先将作业随机排列,然后轮流分配到各小的Cell中。图7确认了使用小型Cell需要增加相当多的机器。
5.4 细粒度资源请求 Fine-grained resource requests
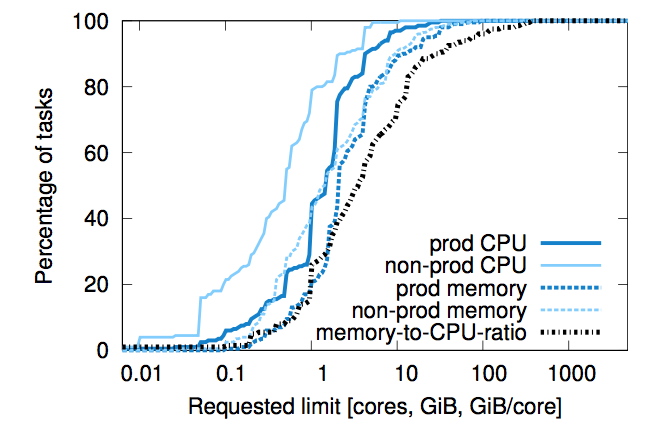
Figure 8: No bucket sizes fit most of the tasks well. CDF of requested CPU and memory requests across our sample cells. No one value stands out, although a few integer CPU core sizes are somewhat more popular.
Borg users request CPU in units of milli-cores, and memory and disk space in bytes. (A core is a processor hyperthread, normalized for performance across machine types.) Figure 8 shows that they take advantage of this granularity: there are few obvious “sweet spots” in the amount of memory or CPU cores requested, and few obvious correlations between these resources. These distributions are quite similar to the ones presented in [68], except that we see slightly larger memory requests at the 90%ile and above.
Borg用户请求的CPU单位是0.001个核,内存和硬盘的单位是字节。(一个核实际上是一个CPU的超线程,对不同机器类型的性能进行了标准化)。图8表明用户充分利用了细粒度:请求的CPU核和内存数量的“特别偏好值”是很少的,这些资源也没有明显的相关性。这与[68]里的分布非常相似,除了我们在90%分位数及以上的内存请求多一点之外。
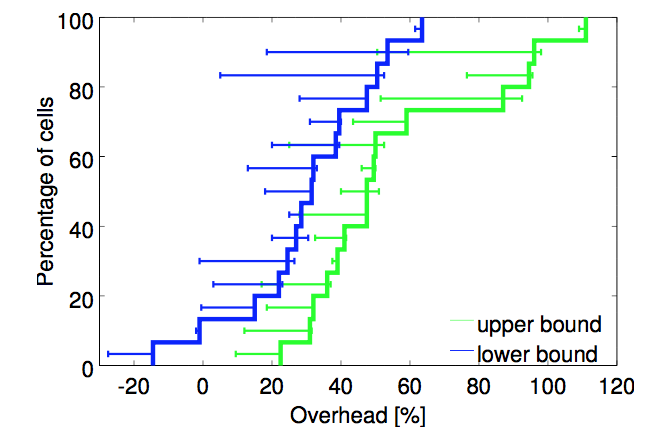
Figure 9: “Bucketing” resource requirements would need more machines. A CDF of the additional overheads that would result from rounding up CPU and memory requests to the next nearest powers of 2 across 15 cells. The lower and upper bounds straddle the actual values (see the text).
Offering a set of fixed-size containers or virtual machines, although common among IaaS (infrastructure-as-a-service) providers [7, 33], would not be a good match to our needs. To show this, we “bucketed” CPU core and memory resource limits for prod jobs and allocs (§2.4) by rounding them up to the next nearest power of two in each resource dimension, starting at 0.5 cores for CPU and 1 GiB for RAM. Figure 9 shows that doing so would require 30–50% more resources in the median case. The upper bound comes from allocating an entire machine to large tasks that didn’t fit after quadrupling the original cell before compaction began; the lower bound from allowing these tasks to go pending. (This is less than the roughly 100% overhead reported in [37] because we supported more than 4 buckets and permitted CPU and RAM capacity to scale independently.)
尽管IaaS普遍只提供一组固定尺寸的容器或虚拟机[7, 33],但不符合我们的需求。为说明这一点,我们对prod的作业和Alloc(§2.4)申请的CPU核和内存分别向上取整到最接近的2的幂,形成固定大小的“桶”,最小的桶有0.5个核和1GiB内存。图9显示一般情况下这样需要增加30-50%的资源。上限的情形是,有的大型任务即便将Cell扩大为未压缩尺寸的四倍也无法容纳,只好为其分配一整台机器。下限是允许这些任务一直等待。(这比[37]给出的将近100%的额外开销要小一些,因为我们支持不止4种尺寸的桶,而且允许CPU和内存分别改变)。
5.5 资源回收 Resource reclamation
A job can specify a resource limit – an upper bound on the resources that each task should be granted. The limit is used by Borg to determine if the user has enough quota to admit the job, and to determine if a particular machine has enough free resources to schedule the task. Just as there are users who buy more quota than they need, there are users who request more resources than their tasks will use, because Borg will normally kill a task that tries to use more RAM or disk space than it requested, or throttle CPU to what it asked for. In addition, some tasks occasionally need to use all their resources (e.g., at peak times of day or while coping with a denial-of-service attack), but most of the time do not.
作业可以声明一个资源限额(Limit),是每个任务能获得的资源上限。Borg会用它来检查用户是否有足够的配额来接受该作业,并检查某个机器是否有足够的可用资源来运行任务。因为Borg通常会杀死那些试图使用超出内存和硬盘申请值的任务,或者限制其CPU使用量不超过申请值,所以有的用户会为任务申请超过实际需要的资源,就像有的用户会购买超过实际需要的配额一样。另外,一些任务只是偶尔需要使用它们申请的所有资源(例如,在一天中的高峰期或者受到了拒绝服务攻击),但大多时候用不了。
Rather than waste allocated resources that are not currently being consumed, we estimate how many resources a task will use and reclaim the rest for work that can tolerate lower-quality resources, such as batch jobs. This whole process is called resource reclamation. The estimate is called the task’s reservation, and is computed by the Borgmaster every few seconds, using fine-grained usage (resource-consumption) information captured by the Borglet. The initial reservation is set equal to the resource request (the limit); after 300 s, to allow for startup transients, it decays slowly towards the actual usage plus a safety margin. The reservation is rapidly increased if the usage exceeds it.
与其把那些分配出来但暂时没有被用到的资源浪费掉,我们估计了一个任务会用多少资源,然后把剩余的资源回收给那些可以忍受低质量资源的任务,例如批处理作业。这整个过程称为资源再利用。这个估值称为任务的资源预留(Reservation)。Borgmaster每隔几秒就会根据Borglet获取的细粒度资源使用量信息来计算一次预留值。最初的预留资源被设置为资源限额;在300秒之后,也就过了启动阶段,预留资源会缓慢的下降到实际使用量加上一个安全值。在实际使用量超过它时,预留值会迅速增加。
The Borg scheduler uses limits to calculate feasibility (§3.2) for prod tasks,4 so they never rely on reclaimed resources and aren’t exposed to resource oversubscription; fornon-prod tasks, it uses the reservations of existing tasks so the new tasks can be scheduled into reclaimed resources.
Borg调度器使用资源限额来计算prod级任务(注:准确的说,是高优先级的、延迟敏感的任务,见§6.2)是否可以执行(§3.2),所以这些任务不依赖于回收的资源,也与资源超售无关;对于non-prod的任务,运行任务使用的资源在预留值之内,这样新任务就可以使用回收的资源。
A machine may run out of resources at runtime if the reservations (predictions) are wrong – even if all tasks use less than their limits. If this happens, we kill or throttle non-prod tasks, never prod ones.
一台机器有可能因为预留(预测)错误而导致运行时资源不足 —— 即使所有的任务都在资源限额之内。如果这种情况发生了,我们会杀掉或者限制non-prod任务,但从来不对prod任务下手。
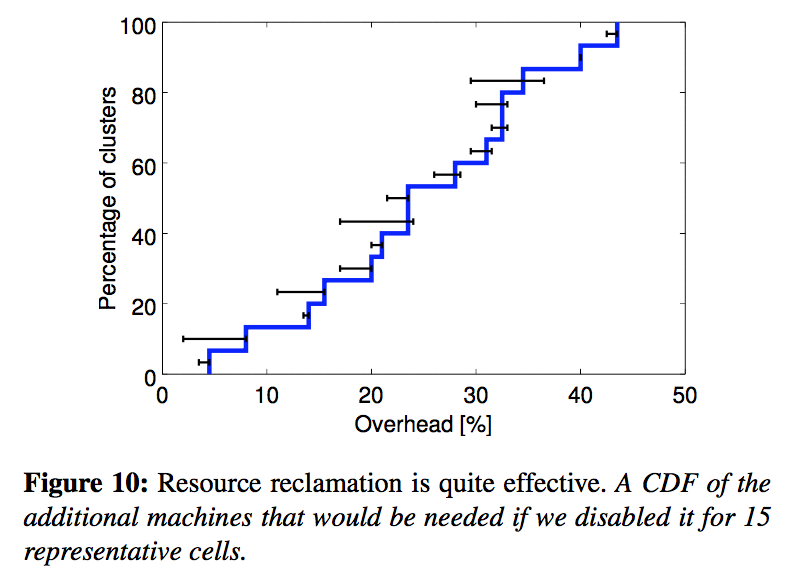
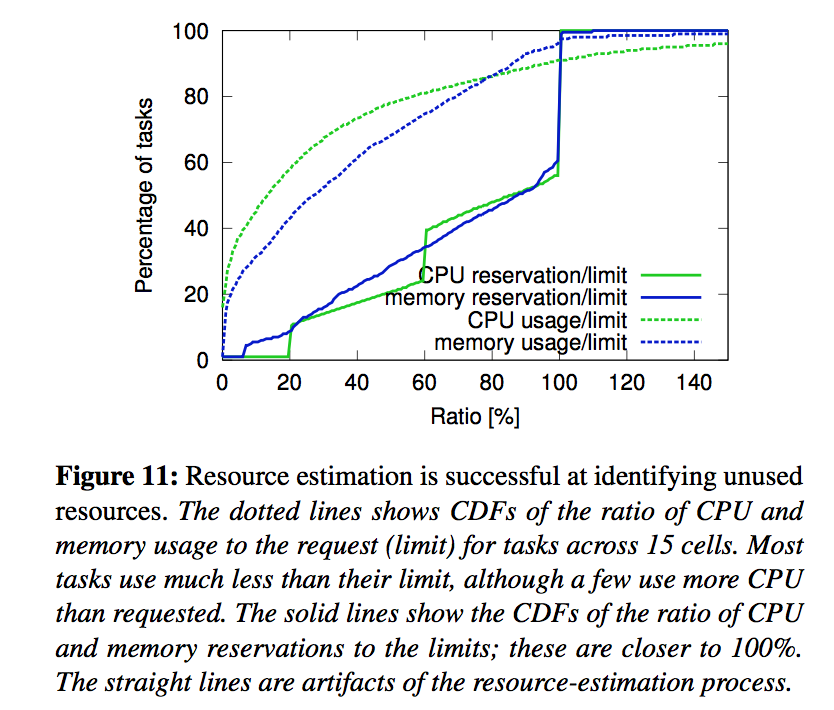
Figure 10 shows that many more machines would be required without resource reclamation. About 20% of the workload (§6.2) runs in reclaimed resources in a median cell.
图10表明,如果没有资源回收,将需要更多的机器。在一个中等规模的Cell中大概有20%的工作负载(§6.2)使用了回收的资源。
We can see more details in Figure 11, which shows the ratio of reservations and usage to limits. A task that exceeds its memory limit will be the first to be preempted if resources are needed, regardless of its priority, so it is rare for tasks to exceed their memory limit. On the other hand, CPU can readily be throttled, so short-term spikes can push usage above reservation fairly harmlessly.
图11可以看到更多的细节,其中有预留值、使用量与限额的比例。当资源紧张时,超出内存限额的任务首先会被抢占,不论优先级有多高,所以很少有任务超过内存限额。另一方面,CPU使用量是可以被轻易限制住的,所以短时的毛刺虽然会导致使用量超过预留值,但这没什么损害。
Figure 11 suggests that resource reclamation may be unnecessarily conservative: there is significant area between the reservation and usage lines. To test this, we picked a live production cell and adjusted the parameters of its resource estimation algorithm to an aggressive setting for a week by reducing the safety margin, and then to an medium setting that was mid-way between the baseline and aggressive settings for the next week, and then reverted to the baseline.
图11表明了资源回收可能还过于保守:在预留值和实际使用量中间还有一大段差距。为了测试这一点,我们选择了一个线上Cell,(第一周作为参照基准,)第二周将其估计算法的参数调整为比较激进的设置,即把安全裕度留小一点;第三周采取的是介于激进和基准之间的适度策略,最后一周恢复到基准策略。
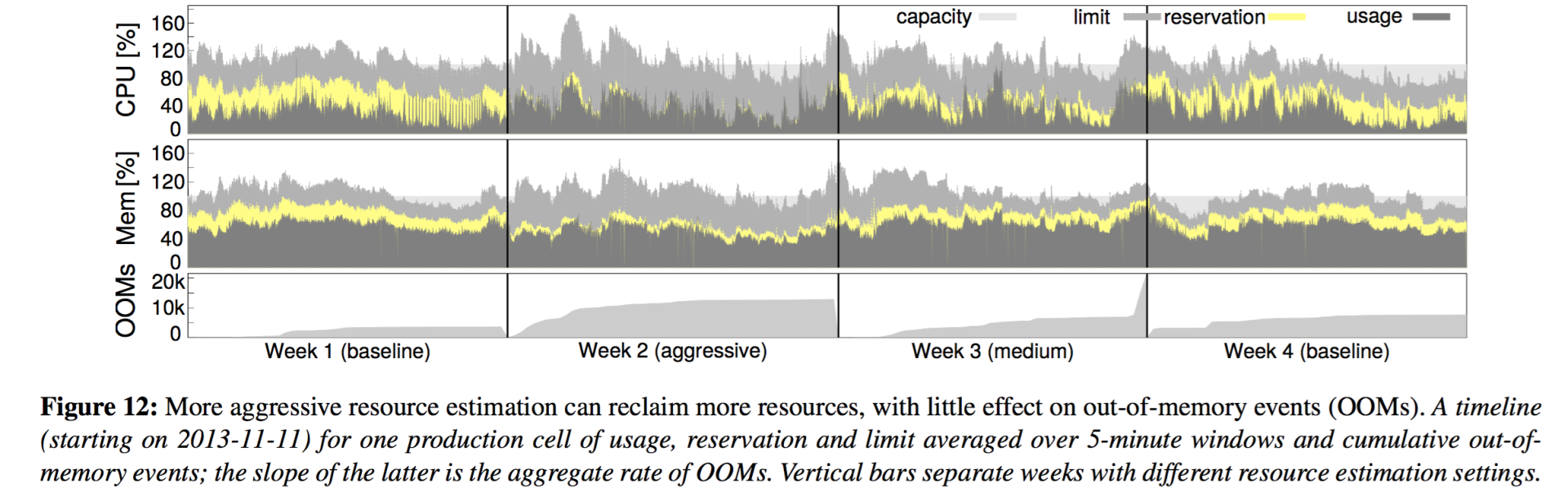
图12. 更激进的资源估计可以回收更多资源,但会稍增加OOM事件
Figure 12 shows what happened. Reservations are clearly closer to usage in the second week, and somewhat less so in the third, with the biggest gaps shown in the baseline weeks (1st and 4th). As anticipated, the rate of out-of-memory (OOM) events increased slightly in weeks 2 and 3.5 After reviewing these results, we decided that the net gains out-weighed the downsides, and deployed the medium resource reclamation parameters to other cells.
图12展示了结果。第二周的预留值明显更接近实际使用量,第三周稍大一点,最大的是第一周和第四周。和预期的一样,第二周和第三周的OOM比率轻微地增加了(注:第3周后期的异常情况与本次实验无关)。在评估了这个结果后,我们认为利大于弊,于是在其它Cell上也采用了适度策略的资源回收参数。
6. 隔离 Isolation
50% of our machines run 9 or more tasks; a 90%ile machine has about 25 tasks and will be running about 4500 threads[83]. Although sharing machines between applications increases utilization, it also requires good mechanisms to prevent tasks from interfering with one another. This applies to both security and performance.
50%的机器运行了9个以上的任务;处于90%分位数的机器则有大约25个任务,4500个线程[83]。虽然在应用之间共享机器会增加利用率,但也需要一个比较好的机制来保证任务之间不产生干扰。这同时适用于安全和性能两个方面。
6.1 安全隔离
We use a Linux chroot jail as the primary security isolation mechanism between multiple tasks on the same machine. To allow remote debugging, we used to distribute (and rescind)ssh keys automatically to give a user access to a machine only while it was running tasks for the user. For most users, this has been replaced by the borgssh command, which collaborates with the Borglet to construct an ssh connection to a shell that runs in the same chroot and cgroup as the task, locking down access even more tightly.
我们使用Linux的chroot作为同一台机器上不同任务之间的主要安全隔离机制。仅当某台机器有用户运行的任务时,为了允许远程调试,我们以前会自动分发(或废除)SSH秘钥,使用户可以访问这台机器。对大多数用户来说,现在被替换为borgssh命令,这个程序和Borglet协同构建一个SSH通道,连接到与任务运行在同一个chroot和cgroup下的Shell,这样限制就更加严格了。
VMs and security sandboxing techniques are used to run external software by Google’s AppEngine (GAE) [38] and Google Compute Engine (GCE). We run each hosted VM in a KVM process [54] that runs as a Borg task.
Google的AppEngine(GAE)[38]和Google Compute Engine(GCE)使用VM和安全沙箱技术运行外部的软件。我们把每个运行在KVM进程中的VM作为一个Borg任务来运行。
6.2 性能隔离 Performance isolation
Early versions of Borglet had relatively primitive resource isolation enforcement: post-hoc usage checking of memory, disk space and CPU cycles, combined with termination of tasks that used too much memory or disk and aggressive application of Linux’s CPU priorities to rein in tasks that used too much CPU. But it was still too easy for rogue tasks to affect the performance of other tasks on the machine, so some users inflated their resource requests to reduce the number of tasks that Borg could co-schedule with theirs, thus decreasing utilization. Resource reclamation could claw back some of the surplus, but not all, because of the safety margins involved. In the most extreme cases, users petitioned to use dedicated machines or cells.
早期的Borglet使用了一种相对原始的资源隔离措施:事后检查内存、硬盘和CPU使用量,终止使用过多内存和硬盘的任务,或者降低使用过多CPU的任务的Linux CPU优先级。不过,一些粗暴的任务还是能很容易地影响到同台机器上其它任务的性能,于是有的用户就会多申请资源来让Borg减少与其共存的任务数量,降低了资源利用率。资源回收可以弥补一些损失,但不是全部,因为涉及到安全裕度。在极端情况下,用户会要求使用专属的机器或者Cell。
Now, all Borg tasks run inside a Linux cgroup-based resource container [17, 58, 62] and the Borglet manipulates the container settings, giving much improved control because the OS kernel is in the loop. Even so, occasional low-level resource interference (e.g., memory bandwidth or L3 cache pollution) still happens, as in [60, 83].
目前,所有Borg任务都运行在基于Linux cgroup的资源容器[17, 58, 62]里。Borglet控制着这些容器的设置。有了OS内核的帮助,控制能力得到了改善。即使这样,偶尔还是有底层的资源发生冲突(例如内存带宽或L3缓存污染),见[60, 83]。
To help with overload and overcommitment, Borg tasks have an application class or appclass. The most important distinction is between the latency-sensitive (LS) appclasses and the rest, which we call batch in this paper. LS tasks are used for user-facing applications and shared infrastructure services that require fast response to requests. High-priority LS tasks receive the best treatment, and are capable of temporarily starving batch tasks for several seconds at a time.
为了应对过载和超售,Borg任务有一个应用类别(appclass)属性。最重要的区分是延迟敏感(LS)的应用和本文中称为批处理(batch)的其它类别。LS任务包括面向用户的应用和需要快速响应的共享基础设施。高优先级的LS任务得到最高优待,可以暂时让批处理任务等待几秒种。
A second split is between compressible resources (e.g., CPU cycles, disk I/O bandwidth) that are rate-based and can be reclaimed from a task by decreasing its quality of service without killing it; and non-compressible resources (e.g., memory, disk space) which generally cannot be reclaimed without killing the task. If a machine runs out of non-compressible resources, the Borglet immediately terminates tasks, from lowest to highest priority, until the remaining reservations can be met. If the machine runs out of compressible resources, the Borglet throttles usage (favoring LS tasks) so that short load spikes can be handled without killing any tasks. If things do not improve, Borgmaster will remove one or more tasks from the machine.
第二个区分是:可压缩资源(例如CPU,硬盘I/O带宽),都是基于速率的,可以通过降低一个任务的服务质量而不是杀死它来回收;不可压缩资源(例如内存、硬盘空间),这些一般来说不杀掉任务是没办法回收的。如果一个机器用光了不可压缩资源,Borglet马上就会开始杀死任务,从低优先级开始,直到能满足剩下的资源预留。如果机器用完了可压缩资源,Borglet会限制使用量(偏好LS任务),这样不用杀死任何任务也能处理短期负载尖峰。如果情况没有改善,Borgmaster会从这个机器上移除一个或多个任务。
A user-space control loop in the Borglet assigns memory to containers based on predicted future usage (for prodtasks) or on memory pressure (for non-prod ones); handles Out-of-Memory (OOM) events from the kernel; and kills tasks when they try to allocate beyond their memory limits, or when an over-committed machine actually runs out of memory. Linux’s eager file-caching significantly complicates the implementation because of the need for accurate memory-accounting.
Borglet有一个用户态的控制循环,负责以下操作:为容器确定内存量,prod任务基于预测值,而non-prod任务则基于内存压力;处理来自内核的OOM事件;当任务试图分配超过其自身限额的内存时,或者超售的机器上确实耗尽内存时,都会杀死任务。Linux激进的文件缓存让我们的实现复杂得多,因为需要精确计算内存使用量。
To improve performance isolation, LS tasks can reserve entire physical CPU cores, which stops other LS tasks from using them. Batch tasks are permitted to run on any core, but they are given tiny scheduler shares relative to the LS tasks. The Borglet dynamically adjusts the resource caps of greedy LS tasks in order to ensure that they do not starve batch tasks for multiple minutes, selectively applying CFS bandwidth control when needed [75]; shares are insufficient because we have multiple priority levels.
为了增强性能隔离,LS任务可以预留整个物理CPU核,以阻止别的LS任务来使用它们。批处理任务被允许运行在任何核上,但是相比LS任务,批处理任务只分配了很少的调度份额。Borglet动态地调整贪婪的LS任务的资源上限,以保证它们不会把批处理任务饿上几分钟,必要时有选择的使用CFS带宽控制[75];仅用份额来表示是不够的,因为我们有多个优先级。
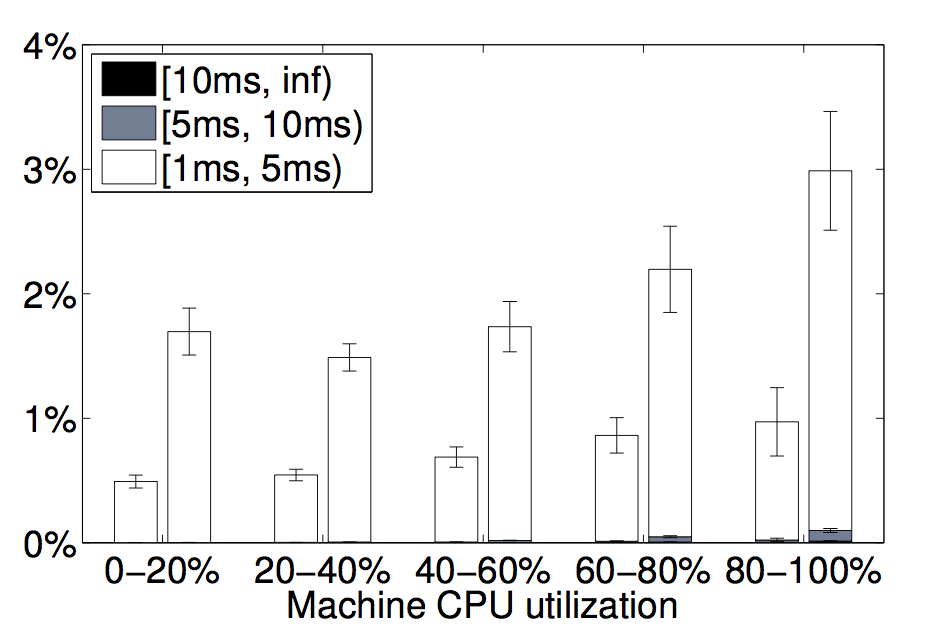
Figure 13: Scheduling delays as a function of load. A plot of how often a runnable thread had to wait longer than 1ms to get access to a CPU, as a function of how busy the machine was. In each pair of bars, latency-sensitive tasks are on the left, batch ones on the right. In only a few percent of the time did a thread have to wait longer than 5 ms to access a CPU (the white bars); they almost never had to wait longer (the darker bars). Data from a representative cell for the month of December 2013; error bars show day-to-day variance.
图13. 调度延迟与负载的关系。即一个就绪线程需要等待超过1 ms才能运行的比率,与机器繁忙程度的关系。每组数据条中,左侧是延迟敏感的任务,右侧是批处理任务。只有很少的比率需要等5 ms以上,超过10 ms就极少了。这是2013年12月从一个代表性的Cell中获取的一个月的数据;误差线是每天的波动
Like Leverich [56], we found that the standard Linux CPU scheduler (CFS) required substantial tuning to support both low latency and high utilization. To reduce scheduling delays, our version of CFS uses extended per-cgroup load history [16], allows preemption of batch tasks by LS tasks, and reduces the scheduling quantum when multiple LS tasks are runnable on a CPU. Fortunately, many of our applications use a thread-per-request model, which mitigates the effects of persistent load imbalances. We sparingly usecpusets to allocate CPU cores to applications with particularly tight latency requirements. Some results of these efforts are shown in Figure 13. Work continues in this area, adding thread placement and CPU management that is NUMA-, hyperthreading-, and power-aware (e.g., [81]), and improving the control fidelity of the Borglet.
同Leverich[56]一样,我们发现标准的Linux CPU调度器(CFS)需要大幅调整才能同时支持低延迟和高利用率。为了减少调度延迟:我们内部版本的CFS对每个cgroup都有单独的负载历史 [16];允许LS任务抢占批处理任务;当一个CPU有多个就绪的LS任务时,会减少其调度量(Quantum)。幸运的是,我们的大多应用使用一个线程处理一个请求的模型,这样就缓解了持续的负载失衡。我们节俭地使用 cpusets为有特别严格的延迟需求的应用分配CPU核。这些努力的一些效果展示在图13中。我们持续在这方面投入,增加感知NUMA、超线程、能耗(如 [81])的线程放置和CPU管理,改进Borglet的控制精确度。
Tasks are permitted to consume resources up to their limit. Most of them are allowed to go beyond that for compressible resources like CPU, to take advantage of unused (slack) resources. Only 5% of LS tasks disable this, presumably to get better predictability; fewer than 1% of batch tasks do. Using slack memory is disabled by default, because it increases the chance of a task being killed, but even so, 10% of LS tasks override this, and 79% of batch tasks do so because it’s a default setting of the MapReduce framework. This complements the results for reclaimed resources (§5.5). Batch tasks are willing to exploit unused as well as reclaimed memory opportunistically: most of the time this works, although the occasional batch task is sacrificed when an LS task needs resources in a hurry.
任务被允许在其上限之内消费资源。大部分任务还允许去使用超出上限的可压缩资源,例如CPU,以利用空闲资源。只有5%的LS任务禁止这么做,主要是为了改善可预测性;小于1%的批处理任务也禁止了。使用超量内存默认是被禁止的,因为这会增加任务被杀掉的概率,不过即使这样,10%的LS任务解除了这个限制,79%的批处理任务也解除了,因为这是MapReduce框架的默认设置。这补偿了资源回收(§5.5)的后果。批处理任务很乐意使用空闲的或回收的内存:大多情况下这样运作得很好,即使偶尔批处理任务会被急需资源的LS任务杀掉。
7. 相关工作 Related work
Resource scheduling has been studied for decades, in contexts as varied as wide-area HPC supercomputing Grids, networks of workstations, and large-scale server clusters. We focus here on only the most relevant work in the context of large-scale server clusters.
数十年来,资源调度已经在多种场景得到了研究,如广域高性能计算网格、工作站网络、和大规模服务器集群等。我们这里只关注最相关的大规模服务器集群这个场景。
Several recent studies have analyzed cluster traces from Yahoo!, Google, and Facebook [20, 52, 63, 68, 70, 80, 82], and illustrate the challenges of scale and heterogeneity inherent in these modern datacenters and workloads. [69] contains a taxonomy of cluster manager architectures.
最近的一些研究分析了来自于Yahoo!、Google和Facebook的集群记录数据[20, 52, 63, 68, 70, 80, 82],展现了这些现代的数据中心和工作负载固有的异构性和大规模带来的挑战。[69]包含了对集群管理器架构的分类。
Apache Mesos [45] splits the resource management and placement functions between a central resource manager (somewhat like Borgmaster minus its scheduler) and multiple “frameworks” such as Hadoop [41] and Spark [73] using an offer-based mechanism. Borg mostly centralizes these functions using a request-based mechanism that scales quite well. DRF [29, 35, 36, 66] was initially developed for Mesos; Borg uses priorities and admission quotas instead. The Mesos developers have announced ambitions to extend Mesos to include speculative resource assignment and reclamation, and to fix some of the issues identified in [69].
Apache Mesos[45]将资源管理和任务放置功能拆分到一个集中资源管理器(类似于去掉调度器的Bormaster)和多种“框架”(比如Hadoop[41]和Spark[73])之间,两者基于供应(Offer)机制交互。Borg则把这些功能集中在一起,使用基于请求的机制,而且扩展性相当好。DRF[29, 35, 36, 66]最初是为Mesos开发的;Borg则使用优先级和准入配额来替代。Mesos开发者已经宣布了他们扩展Mesos的雄心壮志:预测性资源分配和回收,以及解决[69]中发现的一些问题。
YARN [76] is a Hadoop-centric cluster manager. Each application has a manager that negotiates for the resources it needs with a central resource manager; this is much the same scheme that Google MapReduce jobs have used to obtain resources from Borg since about 2008. YARN’s resource manager only recently became fault tolerant. A related open-source effort is the Hadoop Capacity Scheduler [42] which provides multi-tenant support with capacity guarantees, hierarchical queues, elastic sharing and fairness. YARN has recently been extended to support multiple resource types, priorities, preemptions, and advanced admission control [21]. The Tetris research prototype [40] supports makespan-aware job packing.
YARN[76]是一个针对Hadoop的集群管理器。每个应用都有一个另外的管理器,与中央资源管理器谈判所需资源;这跟大约2008年开始Google的MapReduce作业已经使用的向Borg获取资源的模式如出一辙。YARN的资源管理器最近才支持容错。一个相关的开源项目是Hadoop Capacity Scheduler(基于容量的调度器)[42],提供了多租户下的容量保证、多层队列、弹性共享和公平调度。YARN最近扩展支持了多种资源类型、优先级、抢占和高级准入控制[21]。Tetris(俄罗斯方块)研究原型[40]支持完成时间感知的作业装箱。
Facebook’s Tupperware [64], is a Borg-like system for scheduling cgroup containers on a cluster; only a few details have been disclosed, although it seems to provide a form of resource reclamation. Twitter has open-sourced Aurora [5], a Borg-like scheduler for long running services that runs on top of Mesos, with a configuration language and state machine similar to Borg’s.
Facebook的Tupperware[64],是一个在集群中调度cgroup容器的类Borg系统;只有少量细节披露出来了,看起来它也提供了某种形式的资源回收功能。Twitter开源的Aurora[5]是一个类似Borg的,用于长期运行服务的调度器,运行与Mesos之上,其配置语言和状态迁移与Borg类似。
The Autopilot system from Microsoft [48] provides “automating software provisioning and deployment; system monitoring; and carrying out repair actions to deal with faulty software and hardware” for Microsoft clusters. The Borg ecosystem provides similar features, but space precludes a discussion here; Isaard [48] outlines many best practices that we adhere to as well.
微软的Autopilot[48]为其集群提供了“自动化的软件供应和部署;系统监控;以及采取修复行为处理软硬件故障”的功能。Borg生态系统提供了相似的特性,不过篇幅所限,不再深入讨论;作者Isaard概括了很多我们也赞成的最佳实践。
Quincy [49] uses a network flow model to provide fairness- and data locality-aware scheduling for data-processing DAGs on clusters of a few hundred nodes. Borg uses quota and priorities to share resources among users and scales to tens of thousands of machines. Quincy handles execution graphs directly while this is built separately on top of Borg.
Quincy[49]使用了一个网络流模型来提供公平性和数据局部性感知的调度,应用在几百个节点的集群的数据处理DAG上。Borg使用配额和优先级在用户间共享数据,可以扩展到上万台机器。Quincy可以直接处理执行图,而Borg需要在其上层另外构建。
Cosmos [44] focuses on batch processing, with an emphasis on ensuring that its users get fair access to resources they have donated to the cluster. It uses a per-job manager to acquire resources; few details are publicly available.
Cosmos[44]聚焦在批处理上,强调了用户可以公平获取他们已经捐献给集群的资源。每个作业分别有一个管理器来获取资源;只有很少公开的细节。
Microsoft’s Apollo system [13] uses per-job schedulers for short-lived batch jobs to achieve high throughput on clusters that seem to be comparably-sized to Borg cells. Apollo uses opportunistic execution of lower-priority background work to boost utilization to high levels at the cost of (sometimes) multi-day queueing delays. Apollo nodes provide a prediction matrix of starting times for tasks as a function of size over two resource dimensions, which the schedulers combine with estimates of startup costs and remote-data-access to make placement decisions, modulated by random delays to reduce collisions. Borg uses a central scheduler for placement decisions based on state about prior allocations, can handle more resource dimensions, and focuses on the needs of high-availability, long-running applications; Apollo can probably handle a higher task arrival rate.
微软的Apollo系统[13]为每个短期批处理作业分别使用单独的调度器,以获得高吞吐量,其集群规模看起来与Borg的Cell相当。Apollo投机地执行低优先级后台任务来提升资源利用率,代价是有时有长达多日的队列延迟。Apollo的各节点都一个关于开始时间的预测矩阵,其行列分别为CPU和内存两个资源维度。调度器会综合开始时间、估计的启动开销、获取远程数据的开销来决定部署位置,并用一个随机延时来减少冲突。Borg使用的是中央调度器,基于之前的分配来决定部署位置,可以处理更多的资源维度,而且更关注高可用、长期运行的应用;Apollo也许能处理比Borg更高的任务到达率。
Alibaba’s Fuxi [84] supports data-analysis workloads; it has been running since 2009. Like Borgmaster, a central FuxiMaster (replicated for failure-tolerance) gathers resource-availability information from nodes, accepts requests from applications, and matches one to the other. The Fuxi incremental scheduling policy is the inverse of Borg’s equivalence classes: instead of matching each task to one of a suitable set of machines, Fuxi matches newly-available resources against a backlog of pending work. Like Mesos, Fuxi allows “virtual resource” types to be defined. Only synthetic workload results are publicly available.
阿里巴巴的伏羲(Fuxi)[84]支持数据分析的负载,从2009年就开始运行了。类似Borgmaster,一个集中的FuxiMaster(也做了容错多副本)从节点上获取可用资源的信息、接受应用的资源请求,然后匹配两者。伏羲的增量调度策略与Borg的任务等价类是相反的:伏羲用最新的可用资源匹配等待队列里的任务(译注:Borg是用任务匹配资源)。类似Mesos,伏羲允许定义“虚拟资源”类型。只有对合成工作负载的实验结果是公开的。
Omega [69] supports multiple parallel, specialized “verticals” that are each roughly equivalent to a Borgmaster minus its persistent store and link shards. Omega schedulers use optimistic concurrency control to manipulate a shared representation of desired and observed cell state stored in a central persistent store, which is synced to/from the Borglets by a separate link component. The Omega architecture was designed to support multiple distinct workloads that have their own application-specific RPC interface, state machines, and scheduling policies (e.g., long-running servers, batch jobs from various frameworks, infrastructure services like cluster storage systems, virtual machines from the Google Cloud Platform). On the other hand, Borg offers a “one size fits all” RPC interface, state machine semantics, and scheduler policy, which have grown in size and complexity over time as a result of needing to support many disparate workloads, and scalability has not yet been a problem (§3.4).
Omega[69]支持多个并发的调度器,粗略相当于没有持久存储和链接分片的Borgmaster。Omega调度器使用乐观并发控制的方式去操作一个共享的集群预期的和观察的状态表示。集群状态存储在一个集中持久存储中,用单独的连接组件与Borglet同步。Omage架构设计为支持多种不同的工作负载,它们有自己特定的RPC接口、状态迁移和调度策略(例如长期运行的服务、多个框架批处理作业、如集群存储这样的基础服务、Google云平台上的虚拟机)。相反,Borg提供了一种通用方案,同样的RPC接口、状态迁移、调度策略,为支持多种不同的负载,其规模和复杂度逐渐增加,但目前来说可扩展性还不算一个问题(§3.4)。
Google’s open-source Kubernetes system [53] places applications in Docker containers [28] onto multiple host nodes. It runs both on bare metal (like Borg) and on various cloud hosting providers, such as Google Compute Engine. It is under active development by many of the same engineers who built Borg. Google offers a hosted version called Google Container Engine [39]. We discuss how lessons from Borg are being applied to Kubernetes in the next section.
Google的开源项目Kubernetes系统[53]把应用放在Docker容器内[28],再分发到多个机器上。它既可以运行在物理机上(像Borg那样),也可以运行在多个云供应商(比如Google Compute Engine,GCE)的主机上。Kubernetes正在快速开发中,它的很多开发者也参与开发了Borg。Google提供了一个托管的版本,称为Google Container Engine(GKE)[39]。我们会在下一节里面讨论Kubernetes从Borg中学到了哪些东西。
The high-performance computing community has a long tradition of work in this area (e.g., Maui, Moab, Platform LSF [2, 47, 50]); however the requirements of scale, workloads and fault tolerance are different from those of Google’s cells. In general, such systems achieve high utilization by having large backlogs (queues) of pending work.
在高性能计算社区对这个领域有长期的研究传统(如Maui, Moab, Platform LSF[2, 47, 50]);但是这和Google Cell所面对的规模、工作负载、容错性是不同的。总体而言,为达到高用率,这些系统需要让任务在一个很长的队列中等待。
Virtualization providers such as VMware [77] and data-center solution providers such as HP and IBM [46] provide cluster management solutions that typically scale to O(1000) machines. In addition, several research groups have prototyped systems that improve the quality of scheduling decisions in certain ways (e.g., [25, 40, 72, 74]).
虚拟化供应商,例如VMware[77],和数据中心方案供应商,例如HP和IBM[46]提供了典型情况下可以扩展到一千台机器规模的集群管理解决方案。另外,一些研究小组的原型系统以多种方式提升了调度质量(如[25, 40, 72, 74])。
And finally, as we have indicated, another important part of managing large scale clusters is automation and “operator scale out”. [43] describes how planning for failures, multitenancy, health checking, admission control, and restartability are necessary to achieve high numbers of machines per operator. Borg’s design philosophy is similar and allows us to support tens of thousands of machines per operator (SRE).
最后,正如我们所指出的,大规模集群管理的另外一个重要部分是自动化和无人化。[43]指出,失效预案、多租户、健康检查、准入控制,以及可重启性对实现单个运维人员管理更多的机器的目标是必要的。Borg的设计哲学也是这样的,而且支撑了我们的每个SRE管理数万台机器。
Borg从它的前任继承了很多东西,即我们内部的全局工作队列(Global Work Queue)系统,它最初是由Jeff Dean,Olcan Sercinoglu, 和Percy Liang开发的。 Conder[85]曾被广泛应用于收集空闲资源,其ClassAds机制[86]支持声明式的语句和自动属性匹配。
#
8. 经验教训和未来工作 Lessons and future work
In this section we recount some of the qualitative lessons we’ve learned from operating Borg in production for more than a decade, and describe how these observations have been leveraged in designing Kubernetes [53].
在这一节中我们介绍了十多年来我们在生产环境运行Borg得到的定性的经验教训,然后介绍设计Kubernetes[53]是如何吸收这些经验的。
8.1 教训 Lessons learned: the bad
We begin with some features of Borg that serve as cautionary tales, and informed alternative designs in Kubernetes.
我们从一些Borg作为反面警示的特性开始,然后介绍Kubernetes的替代方案。
Jobs are restrictive as the only grouping mechanism for tasks. 将作业作为唯一的任务分组机制比较受限
Borg has no first-class way to manage an entire multi-job service as a single entity, or to refer to related instances of a service (e.g., canary and production tracks). As a hack, users encode their service topology in the job name and build higher-level management tools to parse these names. At the other end of the spectrum, it’s not possible to refer to arbitrary subsets of a job, which leads to problems like inflexible semantics for rolling updates and job resizing.
Borg没有内置的方法将多个作业组成单个实体来管理,或将相关的服务实例关联起来(例如,测试通道和生产通道)。作为一个技巧,用户把他们的服务拓扑编码到作业的名称中,然后构建了更高层的管理工具来解析这些名称。这个问题的另外一面是,没办法指向服务的任意子集,这就导致了僵硬的语义,以至于无法滚动升级或改变作业的实例数。
To avoid such difficulties, Kubernetes rejects the job notion and instead organizes its scheduling units (pods) usinglabels – arbitrary key/value pairs that users can attach to any object in the system. The equivalent of a Borg job can be achieved by attaching a job:jobname label to a set of pods, but any other useful grouping can be represented too, such as the service, tier, or release-type (e.g., production, staging, test). Operations in Kubernetes identify their targets by means of a label query that selects the objects that the operation should apply to. This approach gives more flexibility than the single fixed grouping of a job.
为了避免这些困难,Kubernetes不再使用作业这个概念,而是用标签(Label)来组织它的调度单元(Pod)。标签是任意的键值对,用户可以对系统的任何对象打上标签。Borg作业可以等效地通过对一组Pod打上 <作业:作业名> 这样的标签来实现。其它有用的分组方式也可以用标签来表示,例如服务、层级、发布类型(如,生产、就绪、测试)。Kubernetes用标签查询的方式来选取待操作的目标对象。这样就比固定的作业分组更加灵活。
One IP address per machine complicates things. 同一台机器的任务共享一个IP太复杂了
In Borg, all tasks on a machine use the single IP address of their host, and thus share the host’s port space. This causes a number of difficulties: Borg must schedule ports as a resource; tasks must pre-declare how many ports they need, and be willing to be told which ones to use when they start; the Borglet must enforce port isolation; and the naming and RPC systems must handle ports as well as IP addresses.
Borg中,同一台机器上的所有任务都使用主机的同一个IP地址,共享端口空间。这就带来几个麻烦:Borg必须把端口当做资源来调度;任务必须先声明它需要多少端口,而且需要支持启动时传入可用端口号;Borglet必须强制端口隔离;命名和RPC系统必须像IP一样处理端口(译注:最后这一点我认为是必要的)。
Thanks to the advent of Linux namespaces, VMs, IPv6, and software-defined networking, Kubernetes can take a more user-friendly approach that eliminates these complications: every pod and service gets its own IP address, allowing developers to choose ports rather than requiring their software to adapt to the ones chosen by the infrastructure, and removes the infrastructure complexity of managing ports.
多亏了Linux的namespace、虚拟机、IPv6和软件定义网络SDN的出现,Kubernetes可以用一种更用户友好的方式来消解这些复杂性:每个Pod和Service都自己的IP地址,允许开发者选择端口而不是让他们的软件支持基础设施的分配,这也消除了基础设施管理端口的复杂性。
Optimizing for power users at the expense of casual ones. 给资深用户优化而忽略了初级用户
Borg provides a large set of features aimed at “power users” so they can fine-tune the way their programs are run (the BCL specification lists about 230 parameters): the initial focus was supporting the largest resource consumers at Google, for whom efficiency gains were paramount. Unfortunately the richness of this API makes things harder for the “casual” user, and constrains its evolution. Our solution has been to build automation tools and services that run on top of Borg, and determine appropriate settings from experimentation. These benefit from the freedom to experiment afforded by failure-tolerant applications: if the automation makes a mistake it is a nuisance, not a disaster.
Borg提供了一大堆针对“资深用户”的特性,这样他们就可以仔细地调节他们程序的运行方式(BCL规范约有230个参数):开始的目的是为了支持Google的大型资源用户,提升他们的效率会带来显著的效益。但不幸的是,这么复杂的API让初级用户用起来很复杂,而且限制了API的演化。我们的解决方案是在Borg上又做了一些自动化的工具和服务,从实验中决定合理的配置。由于应用支持容错,实验可以自由进行:即使自动化出了问题,也只是小麻烦,不会导致灾难。
8.2 经验 Lessons learned: the good
On the other hand, a number of Borg’s design features have been remarkably beneficial and have stood the test of time.
另一方面,有不少Borg的设计特性是非常有益的,而且经历了时间考验。
Allocs are useful. Alloc是有用的
The Borg alloc abstraction spawned the widely-used logsaver pattern (§2.4) and another popular one in which a simple data-loader task periodically updates the data used by a web server. Allocs and packages allow such helper services to be developed by separate teams. The Kubernetes equivalent of an alloc is the pod, which is a resource envelope for one or more containers that are always scheduled onto the same machine and can share resources. Kubernetes uses helper containers in the same pod instead of tasks in an alloc, but the idea is the same.
Borg的Alloc抽象适用于广泛使用的保存日志模式(§2.4),另一个流行的模式是:一个简单的数据加载任务定期更新Web服务器使用的数据。Alloc和软件包机制允许这些辅助服务由不同的小组开发。Kubernetes对应于Alloc的概念是Pod,它是对一个或多个容器的资源封装,其中的容器共享Pod的资源,而且总是被调度到同一台机器上。Kubernetes使用Pod里的辅助容器来替代Alloc里面的任务,不过思路是一样的。
Cluster management is more than task management. 集群管理不只是任务管理
Although Borg’s primary role is to manage the lifecycles of tasks and machines, the applications that run on Borg benefit from many other cluster services, including naming and load balancing. Kubernetes supports naming and load balancing using the service abstraction: a service has a name and a dynamic set of pods defined by a label selector. Any container in the cluster can connect to the service using the service name. Under the covers, Kubernetes automatically load-balances connections to the service among the pods that match the label selector, and keeps track of where the pods are running as they get rescheduled over time due to failures.
虽然Borg的主要角色是管理任务和机器的生命周期,但Borg上的应用还从其它的集群服务中收益良多,例如域名服务和负载均衡。Kubernetes用Service这个抽象概念来支持域名服务和负载均衡:Service有一个域名和用标签选出的多个Pod的动态集合。集群中的任何容器都可以通过Service域名连接到该服务。幕后,Kubernetes自动将连接到该Service的负载分散到与其标签匹配的Pod之间,由于Pod挂掉后会被重新调度到其它机器上,Kubernetes还会跟踪这些Pod的位置。
Introspection is vital. 自省是至关重要的
Although Borg almost always “just works,” when something goes wrong, finding the root cause can be challenging. An important design decision in Borg was to surface debugging information to all users rather than hiding it: Borg has thousands of users, so “self-help” has to be the first step in debugging. Although this makes it harder for us to deprecate features and change internal policies that users come to rely on, it is still a win, and we’ve found no realistic alternative. To handle the enormous volume of data, we provide several levels of UI and debugging tools, so users can quickly identify anomalous events related to their jobs, and then drill down to detailed event and error logs from their applications and the infrastructure itself.
虽然Borg总体上是工作良好的,但出了问题后,定位根本原因是非常有挑战性的。Borg的一个关键设计选择是把所有的调试信息暴露给用户而不是隐藏起来:Borg有几千个用户,所以“自助”是调试的第一步。虽然一些用户的依赖项让我们难以废弃一些特性或修改内部策略,但这还是成功的,我们还没找到其它实际的替代方式。为管理大量的数据,我们提供了多个层次的UI和调试工具,这样用户就可以快速定位与其作业相关的异常事件,深入挖掘来自其应用和基础设施本身的详细事件和错误日志。
Kubernetes aims to replicate many of Borg’s introspection techniques. For example, it ships with tools such as cAdvisor [15] for resource monitoring, and log aggregation based on Elasticsearch/Kibana [30] and Fluentd [32]. The master can be queried for a snapshot of its objects’ state. Kubernetes has a unified mechanism that all components can use to record events (e.g., a pod being scheduled, a container failing) that are made available to clients.
Kubernetes也计划引入Borg的大部分自省技术。和Kubernetes一起发布了很多工具,比如用于资源监控的cAdvisor[15],它基于Elasticsearch/Kibana[30]和Fluentd[32]聚合日志。Master可以用来查询某个对象的状态快照。Kubernetes提供了一致机制,所有可以记录事件的组件(例如,被调度的Pod、出错的容器)都可以被客户端访问。
The master is the kernel of a distributed system. Master是分布式系统的核心
Borgmaster was originally designed as a monolithic system, but over time, it became more of a kernel sitting at the heart of an ecosystem of services that cooperate to manage user jobs. For example, we split off the scheduler and the primary UI (Sigma) into separate processes, and added services for admission control, vertical and horizontal auto-scaling, re-packing tasks, periodic job submission (cron), workflow management, and archiving system actions for off-line querying. Together, these have allowed us to scale up the workload and feature set without sacrificing performance or maintainability.
Borgmaster最初设计为一个单体的系统,随着时间发展,它演变成了一组服务生态系统的核心。用户作业管理的管理是由这些服务协同完成的。比如,我们把调度器和主要的UI(Sigma)分离成单独的进程,增加了一组服务,包括准入控制、纵向和横向扩展、任务重新装箱、周期性作业提交(cron)、工作流管理,用于离线查询的系统活动归档等。总体而言,这让我们能扩展工作负载和特性集合,但无需牺牲性能和可维护性。
The Kubernetes architecture goes further: it has an API server at its core that is responsible only for processing requests and manipulating the underlying state objects. The cluster management logic is built as small, composable micro-services that are clients of this API server, such as the replication controller, which maintains the desired number of replicas of a pod in the face of failures, and the node controller, which manages the machine lifecycle.
Kubernetes的架构走的更远一些:它的核心是一个仅处理请求和操作底层状态目标的API服务。集群管理逻辑构建为一个小型的、可组合的微服务,作为API服务的客户端,如故障后仍维持Pod副本个数在期望值的副本管理器,以及管理机器生命周期的节点管理器。
8.3 总结 Conclusion
Virtually all of Google’s cluster workloads have switched to use Borg over the past decade. We continue to evolve it, and have applied the lessons we learned from it to Kubernetes.
在过去十年间,所有几乎所有的Google集群负载都迁移到了Borg上。我们仍在持续改进它,并把经验应用到了Kubernetes上。
参考文献
[1] O. A. Abdul-Rahman and K. Aida. Towards understanding the usage behavior of Google cloud users: the mice and elephants phenomenon.In Proc. IEEE Int’l Conf. on Cloud Computing Technology and Science (CloudCom), pages 272–277, Singapore, Dec. 2014. [2] Adaptive Computing Enterprises Inc., Provo, UT. Maui Scheduler Administrator’s Guide, 3.2 edition, 2011. [3] T. Akidau, A. Balikov, K. Bekiroğlu, S. Chernyak, J. Haberman, R. Lax, S. McVeety, D. Mills, P. Nordstrom,and S. Whittle. MillWheel: fault-tolerant stream processing at internet scale, In Proc. Int’l Conf. on Very Large Data Bases (VLDB), pages 734–746, Riva del Garda, Italy, Aug.2013. [4] Y. Amir, B. Awerbuch, A. Barak, R. S. Borgstrom, and A. Keren. An opportunity cost approach for job assignment in a scalable computing cluster, IEEE Trans. Parallel Distrib.Syst., 11(7):760–768, July 2000. [5] Apache Aurora. http://aurora.incubator.apache.org/, 2014. [6] Aurora Configuration Tutorial. https://aurora.incubator.apache.org/documentation/latest/configuration-tutorial/, 2014. [7] AWS. Amazon Web Services VM Instances. http://aws.amazon.com/ec2/instance-types/, 2014. [8] J. Baker, C. Bond, J. Corbett, J. Furman, A. Khorlin, J. Larson, J.-M. Leon, Y. Li, A. Lloyd, and V. Yushprakh. Megastore: Providing scalable, highly available storage for interactive services, In Proc. Conference on Innovative Data Systems Research (CIDR), pages 223–234, Asilomar, CA, USA, Jan. 2011. [9] M. Baker and J. Ousterhout. Availability in the Sprite distributed file system, Operating Systems Review,25(2):95–98, Apr. 1991. [10] L. A. Barroso, J. Clidaras, and U. Hölzle. The datacenter as a computer: an introduction to the design of warehouse-scale machines, Morgan Claypool Publishers, 2nd edition, 2013. [11] L. A. Barroso, J. Dean, and U. Holzle. Web search for a planet: the Google cluster architecture, In IEEE Micro, pages 22–28, 2003. [12] I. Bokharouss. GCL Viewer: a study in improving the understanding of GCL programs, Technical report, Eindhoven Univ. of Technology, 2008. MS thesis. [13] E. Boutin, J. Ekanayake, W. Lin, B. Shi, J. Zhou, Z. Qian, M. Wu, and L. Zhou. Apollo: scalable and coordinated scheduling for cloud-scale computing, In Proc. USENIX Symp. on Operating Systems Design and Implementation (OSDI), Oct. 2014. [14] M. Burrows. The Chubby lock service for loosely-coupled distributed systems, In Proc. USENIX Symp. on Operating Systems Design and Implementation (OSDI), pages 335–350,Seattle, WA, USA, 2006. [15] cAdvisor. https://github.com/google/cadvisor, 2014 [16] CFS per-entity load patches. http://lwn.net/Articles/531853, 2013. [17] cgroups. http://en.wikipedia.org/wiki/Cgroups, 2014. [18] C. Chambers, A. Raniwala, F. Perry, S. Adams, R. R. Henry, R. Bradshaw, and N. Weizenbaum. FlumeJava: easy, efficient data-parallel pipelines, In Proc. ACM SIGPLAN Conf. on Programming Language Design and Implementation (PLDI), pages 363–375, Toronto, Ontario, Canada, 2010. [19] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber. Bigtable: a distributed storage system for structured data, ACM Trans. on Computer Systems, 26(2):4:1–4:26, June 2008. [20] Y. Chen, S. Alspaugh, and R. H. Katz. Design insights for MapReduce from diverse production workloads, Technical Report UCB/EECS–2012–17, UC Berkeley, Jan. 2012. [21] C. Curino, D. E. Difallah, C. Douglas, S. Krishnan, R. Ramakrishnan, and S. Rao. Reservation-based scheduling: if you’re late don’t blame us! In Proc. ACM Symp. on Cloud Computing (SoCC), pages 2:1–2:14, Seattle, WA, USA, 2014. [22] J. Dean and L. A. Barroso. The tail at scale, Communications of the ACM, 56(2):74–80, Feb. 2012. [23] J. Dean and S. Ghemawat. MapReduce: simplified data processing on large clusters, Communications of the ACM, 51(1):107–113, 2008. [24] C. Delimitrou and C. Kozyrakis. Paragon: QoS-aware scheduling for heterogeneous datacenters, In Proc. Int’l Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Mar. 201. [25] C. Delimitrou and C. Kozyrakis. Quasar: resource-efficient and QoS-aware cluster management, In Proc. Int’l Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS), pages 127–144, Salt Lake City, UT, USA, 2014. [26] S. Di, D. Kondo, and W. Cirne. Characterization and comparison of cloud versus Grid workloads, In International Conference on Cluster Computing (IEEE CLUSTER), pages 230–238, Beijing, China, Sept. 2012. [27] S. Di, D. Kondo, and C. Franck. Characterizing cloud applications on a Google data center, In Proc. Int’l Conf. on Parallel Processing (ICPP), Lyon, France, Oct. 2013. [28] Docker Project. https://www.docker.io/, 2014. [29] D. Dolev, D. G. Feitelson, J. Y. Halpern, R. Kupferman, and N. Linial. No justified complaints: on fair sharing of multiple resources, In Proc. Innovations in Theoretical Computer Science (ITCS), pages 68–75, Cambridge, MA, USA, 2012. [30] ElasticSearch. http://www.elasticsearch.org, 2014. [31] D. G. Feitelson. Workload Modeling for Computer Systems Performance Evaluation, Cambridge University Press, 2014. [32] Fluentd. http://www.fluentd.org/, 2014. [33] GCE. Google Compute Engine. http://cloud.google.com/products/compute-engine/, 2014. [34] S. Ghemawat, H. Gobioff, and S.-T. Leung. The Google File System, In Proc. ACM Symp. on Operating Systems Principles (SOSP), pages 29–43, Bolton Landing, NY, USA, 2003. ACM. [35] A. Ghodsi, M. Zaharia, B. Hindman, A. Konwinski, S. Shenker, and I. Stoica. Dominant Resource Fairness: fair allocation of multiple resource types, In Proc. USENIX Symp. on Networked Systems Design and Implementation (NSDI), pages 323–326, 2011. [36] A. Ghodsi, M. Zaharia, S. Shenker, and I. Stoica. Choosy: max-min fair sharing for datacenter jobs with constraints, In Proc. European Conf. on Computer Systems (EuroSys), pages 365–378, Prague, Czech Republic, 2013. [37] D. Gmach, J. Rolia, and L. Cherkasova. Selling T-shirts and time shares in the cloud, In Proc. IEEE/ACM Int’l Symp. on Cluster, Cloud and Grid Computing (CCGrid), pages 539–546, Ottawa, Canada, 2012. [38] Google App Engine. http://cloud.google.com/AppEngine, 2014. [39] Google Container Engine (GKE). https://cloud.google.com/container-engine/, 2015. [40] R. Grandl, G. Ananthanarayanan, S. Kandula, S. Rao, and A. Akella. Multi-resource packing for cluster schedulers, In Proc. ACM SIGCOMM, Aug. 2014. [41] Apache Hadoop Project. http://hadoop.apache.org/, 2009. [42] Hadoop MapReduce Next Generation – Capacity Scheduler. http://hadoop.apache.org/docs/r2.2.0/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html, 2013. [43] J. Hamilton. On designing and deploying internet-scale services. In Proc. Large Installation System Administration Conf. (LISA), pages 231–242, Dallas, TX, USA, Nov. 2007. [44] P. Helland. Cosmos: big data and big challenges. http://research.microsoft.com/en-us/events/fs2011/ helland_cosmos_big_data_and_big_challenges.pdf, 2011. [45] B. Hindman, A. Konwinski, M. Zaharia, A. Ghodsi, A. Joseph, R. Katz, S. Shenker, and I. Stoica. Mesos: a platform for fine-grained resource sharing in the data center. In Proc. USENIX Symp. on Networked Systems Design and Implementation (NSDI), 2011. [46] IBM Platform Computing. http://www-03.ibm.com/systems/technicalcomputing/platformcomputing/products/clustermanager/ index.html. [47] S. Iqbal, R. Gupta, and Y.-C. Fang. Planning considerations for job scheduling in HPC clusters, Dell Power Solutions, Feb. 2005. [48] M. Isaard. Autopilot: Automatic data center management, ACM SIGOPS Operating Systems Review, 41(2), 2007. [49] M. Isard, V. Prabhakaran, J. Currey, U. Wieder, K. Talwar, and A. Goldberg. Quincy: fair scheduling for distributed computing clusters, In Proc. ACM Symp. on Operating Systems Principles (SOSP), 2009. [50] D. B. Jackson, Q. Snell, and M. J. Clement. Core algorithms of the Maui scheduler, In Proc. Int’l Workshop on Job Scheduling Strategies for Parallel Processing, pages 87–102. Springer-Verlag, 2001. [51] M. Kambadur, T. Moseley, R. Hank, and M. A. Kim. Measuring interference between live datacenter applications, In Proc. Int’l Conf. for High Performance Computing, Networking, Storage and Analysis (SC), Salt Lake City, UT, Nov. 2012. [52] S. Kavulya, J. Tan, R. Gandhi, and P. Narasimhan. An analysis of traces from a production MapReduce cluster, In Proc. IEEE/ACM Int’l Symp. on Cluster, Cloud and Grid Computing (CCGrid), pages 94–103, 2010. [53] Kubernetes. http://kubernetes.io, Aug. 2014. [54] Kernel Based Virtual Machine. http://www.linux-kvm.org. [55] L. Lamport. The part-time parliament, ACM Trans. on Computer Systems, 16(2):133–169, May 1998. [56] J. Leverich and C. Kozyrakis. Reconciling high server utilization and sub-millisecond quality-of-service, In Proc. European Conf. on Computer Systems (EuroSys), page 4, 2014. [57] Z. Liu and S. Cho. Characterizing machines and workloads on a Google cluster, In Proc. Int’l Workshop on Scheduling and Resource Management for Parallel and Distributed Systems (SRMPDS), Pittsburgh, PA, USA, Sept. 2012. [58] Google LMCTFY project (let me contain that for you). http://github.com/google/lmctfy, 2014. [59] G. Malewicz, M. H. Austern, A. J. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Czajkowski. Pregel: a system for large-scale graph processing, In Proc. ACM SIGMOD Conference, pages 135–146, Indianapolis, IA, USA, 2010. [60] J. Mars, L. Tang, R. Hundt, K. Skadron, and M. L. Soffa. Bubble-Up: increasing utilization in modern warehouse scale computers via sensible co-locations, In Proc. Int’l Symp. on Microarchitecture (Micro), Porto Alegre, Brazil, 2011. [61] S. Melnik, A. Gubarev, J. J. Long, G. Romer, S. Shivakumar, M. Tolton, and T. Vassilakis. Dremel: interactive analysis of web-scale datasets, In Proc. Int’l Conf. on Very Large Data Bases (VLDB), pages 330–339, Singapore, Sept. 2010. [62] P. Menage. Linux control groups. http://www.kernel.org/doc/Documentation/cgroups/cgroups.txt, 2007–2014. [63] A. K. Mishra, J. L. Hellerstein, W. Cirne, and C. R. Das. Towards characterizing cloud backend workloads: insights from Google compute clusters, ACM SIGMETRICS Performance Evaluation Review, 37:34–41, Mar. 2010. [64] A. Narayanan. Tupperware: containerized deployment at Facebook. http://www.slideshare.net/dotCloud/tupperware-containerized-deployment-at-facebook, June 2014. [65] K. Ousterhout, P. Wendell, M. Zaharia, and I. Stoica. Sparrow: distributed, low latency scheduling, In Proc. ACM Symp. on Operating Systems Principles (SOSP), pages 69–84, Farminton, PA, USA, 2013. [66] D. C. Parkes, A. D. Procaccia, and N. Shah. Beyond Dominant Resource Fairness: extensions, limitations, and indivisibilities, In Proc. Electronic Commerce, pages 808–825, Valencia, Spain, 2012. [67] Protocol buffers. https://developers.google.com/protocol-buffers/, and https://github.com/google/protobuf/, 2014. [68] C. Reiss, A. Tumanov, G. Ganger, R. Katz, and M. Kozuch. Heterogeneity and dynamicity of clouds at scale: Google trace analysis, In Proc. ACM Symp. on Cloud Computing (SoCC), San Jose, CA, USA, Oct. 2012. [69] M. Schwarzkopf, A. Konwinski, M. Abd-El-Malek, and J. Wilkes. Omega: flexible, scalable schedulers for large compute clusters, In Proc. European Conf. on Computer Systems (EuroSys), Prague, Czech Republic, 2013. [70] B. Sharma, V. Chudnovsky, J. L. Hellerstein, R. Rifaat, and C. R. Das. Modeling and synthesizing task placement constraints in Google compute clusters, In Proc. ACM Symp. on Cloud Computing (SoCC), pages 3:1–3:14, Cascais, Portugal, Oct. 2011. [71] E. Shmueli and D. G. Feitelson. On simulation and design of parallel-systems schedulers: are we doing the right thing? IEEE Trans. on Parallel and Distributed Systems, 20(7):983–996, July 2009. [72] A. Singh, M. Korupolu, and D. Mohapatra. Server-storage virtualization: integration and load balancing in data centers, In Proc. Int’l Conf. for High Performance Computing, Networking, Storage and Analysis (SC), pages 53:1–53:12, Austin, TX, USA, 2008. [73] Apache Spark Project. http://spark.apache.org/, 2014. [74] A. Tumanov, J. Cipar, M. A. Kozuch, and G. R. Ganger. Alsched: algebraic scheduling of mixed workloads in heterogeneous clouds, In Proc. ACM Symp. on Cloud Computing (SoCC), San Jose, CA, USA, Oct. 2012. [75] P. Turner, B. Rao, and N. Rao. CPU bandwidth control for CFS, In Proc. Linux Symposium, pages 245–254, July 2010. [76] V. K. Vavilapalli, A. C. Murthy, C. Douglas, S. Agarwal, M. Konar, R. Evans, T. Graves, J. Lowe, H. Shah, S. Seth, B. Saha, C. Curino, O. O’Malley, S. Radia, B. Reed, and E. Baldeschwieler. Apache Hadoop YARN: Yet Another Resource Negotiator, In Proc. ACM Symp. on Cloud Computing (SoCC), Santa Clara, CA, USA, 2013. [77] VMware VCloud Suite. http://www.vmware.com/products/vcloud-suite/. [78] A. Verma, M. Korupolu, and J. Wilkes. Evaluating job packing in warehouse-scale computing, In IEEE Cluster, pages 48–56, Madrid, Spain, Sept. 2014. [79] W. Whitt. Open and closed models for networks of queues, AT&T Bell Labs Technical Journal, 63(9), Nov. 1984. [80] J. Wilkes. More Google cluster data. http://googleresearch.blogspot.com/2011/11/more-google-cluster-data.html, Nov. 2011. [81] Y. Zhai, X. Zhang, S. Eranian, L. Tang, and J. Mars. HaPPy: Hyperthread-aware power profiling dynamically, In Proc. USENIX Annual Technical Conf. (USENIX ATC), pages 211–217, Philadelphia, PA, USA, June 2014. USENIX Association. [82] Q. Zhang, J. Hellerstein, and R. Boutaba. Characterizing task usage shapes in Google’s compute clusters, In Proc. Int’l Workshop on Large-Scale Distributed Systems and Middleware (LADIS), 2011. [83] X. Zhang, E. Tune, R. Hagmann, R. Jnagal, V. Gokhale, and J. Wilkes. CPI2: CPU performance isolation for shared compute clusters, In Proc. European Conf. on Computer Systems (EuroSys), Prague, Czech Republic, 2013. [84] Z. Zhang, C. Li, Y. Tao, R. Yang, H. Tang, and J. Xu. Fuxi: a fault-tolerant resource management and job scheduling system at internet scale, In Proc. Int’l Conf. on Very Large Data Bases (VLDB), pages 1393–1404. VLDB Endowment Inc., Sept. 2014. [85] Michael Litzkow, Miron Livny, and Matt Mutka. Condor - A Hunter of Idle Workstations, In Proc. Int’l Conf. on Distributed Computing Systems (ICDCS) , pages 104-111, June 1988. [86] Rajesh Raman, Miron Livny, and Marvin Solomon. Matchmaking: Distributed Resource Management for High Throughput Computing, In Proc. Int’l Symp. on High Performance Distributed Computing (HPDC) , Chicago, IL, USA, July 1998.
