预测相关论文看了不少,但这两篇总能时不时想起来,休假在家想写点啥,就把阅读论文和源码的相关笔记整理了下。
一些HighLight
-
DeepMind总是能发现一些问题领域,适合用机器学习方法重新解一遍题,蛋白质预测、可控核聚变、天气预报,都是。这些场景具备如下特质:1)有充分的历史数据,可以用于模型training;2)问题本身是有规律的,只是这个规律或用数学公式计算困难,或还没有被充分发现(自然科学领域大多具备这一特征);3)当前还没有做的足够好(这个判断并不容易)
-
GraphCast的图结构设计很有意思,点和边是两套东西。点是0.25°经纬度的正方形共721×1440=1,038,240个。但点之间的连接关系并不是按相邻关系定义的,而是构建了multi-mesh,通过把地球表面划分成二十面体,然后再做每个面的三角形一拆四,这样细拆下去6层,共拆出40,962个multi-mesh节点。具有属性的node直接的连接关系,是通过和multi-mesh节点做映射得到的。这么设计的重要原因之一是在真实世界,ERA5等天气数据集就是用0.25°经纬度粒度来记录天气数据的。
-
GraphCast中对GNN & Transformer有一段很有意思的洞见:Transformers结构构建了输入token之间all-to-all的连接关系,类比token是node,图是全连接图。从“定义连接关系”这个视角出发,GNN是灵活性更高的方式,只要想,我们可以在全局任意构建两个node之间的边,但它也带来了代价,就是图的存储、在图上做信息传播,这些的效率都不高。而经典Transformer框架中潜在的连接关系的全连接图,好处是简单,缺点的过于密集的连接带来了过高的计算量,限制了node数量,即在Transformer语境里的context length。长文本Transformer框架是个折中,会构建稀疏化链接,它不像GNN的图定义那么灵活,也减少了经典Transformer的连接密度。而在计算方式上,就没什么区别了,GNN上也能做Attention计算。【A key advantage of GNNs is that the input graph’s structure determines what parts of the rep- resentation interact with one another via learned message-passing, allowing arbitrary patterns of spatial interactions over any range. By contrast, a convolutional neural network (CNN) is restricted to computing interactions within local patches (or, in the case of dilated convolution, over regularly strided longer ranges). And while Transformers (43) can also compute arbitrarily long-range computations, they do not scale well with very large inputs (e.g., the 1 million-plus grid points in GraphCast’s global inputs) because of the quadratic memory complexity induced by computing all-to-all interactions. Contemporary extensions of Transformers often sparsify possible interactions to reduce the complexity, which in effect makes them analogous to GNNs (e.g., graph attention networks (44)).】
-
2024年5月的GenCast基本延续了GraphCast的结构,有两点区别:迭代生成未来T步的输出,用了条件Diffusion;原本只用了MLP,现在改成了Graph Transformer。
GraphCast
1.简介
2022年10月中旬,意大利博洛尼亚,欧洲中期天气预报中心(ECMWF)新建的高性能计算设施正式投入使用,时间是世界协调时间(UTC)05:45。过去几个小时,综合预报系统(IFS)一直在进行复杂的计算,以预测地球未来几天和几周的天气,而它的首次预测刚刚开始向用户发布。这个过程每六小时重复一次,每天进行,以向世界提供最准确的天气预报。
IFS和现代天气预报更广义上的成功,代表了科学和工程的胜利。天气系统的动力学是地球上最复杂的物理现象之一,每天,无数个人、行业和政策制定者的决策依赖于准确的天气预报,从决定是否穿夹克到是否逃避危险的风暴。今天天气预报的主流方法是“数值天气预报”(NWP),它通过超级计算机求解天气的控制方程。NWP的成功源于严格且持续的研究实践,这些实践提供了对天气现象越来越详细的描述,以及NWP如何随着计算资源的增加而精度提升。因此,天气预报的准确性年复一年地提高,甚至可以预测飓风的路径,提前很多天进行预报——这是几十年前根本无法想象的可能性。
然而,尽管传统的NWP在计算上扩展性良好,但利用大量历史天气数据来提高准确性并非易事。NWP方法的改进依赖于经过高度训练的专家,通过创新更好的模型、算法和近似方法,这一过程既耗时又昂贵。
基于机器学习的天气预测(MLWP)为传统的NWP提供了一种替代方案,其中预报模型可以通过历史数据(包括观测和分析数据)进行训练。这有望通过捕捉数据中的模式来提高预测准确性,这些模式在显式方程中不容易表示。MLWP还提供了通过利用现代深度学习硬件而非超级计算机,从而实现更高效率的机会,并能够在速度与精度之间找到更有利的折中。最近,MLWP在传统NWP相对薄弱的领域取得了进展,例如亚季节性的热浪预测和雷达图像降水即时报,这些领域中准确的方程和稳健的数值方法并不容易得到。
在中期天气预报中,即预测最多10天的气象变量,基于NWP的系统,如IFS,仍然是最准确的。世界上最顶尖的确定性操作系统是ECMWF的高分辨率预报(HRES),这是IFS的一种配置,可以在大约一个小时内生成全球10天的预报,分辨率为0.1°经纬度。然而,近年来,基于重分析数据训练的MLWP方法在中期预报中的发展稳步推进,借助WeatherBench等基准测试。基于卷积神经网络和变换器的深度学习架构在分辨率大于1.0°的经纬度范围内取得了有希望的结果,最近的一些研究——使用图神经网络(GNN)、傅里叶神经算子和变换器——报告称,它们的表现开始与IFS在1.0°和0.25°分辨率下的预测相媲美,适用于一些变量,且预报的领先时长可达到7天。
2.GraphCast模型结构概述
在此,我们介绍了一种用于全球中期天气预报的机器学习天气预测(MLWP)方法,称为“GraphCast”。它能够在单个 Google Cloud TPUv4设备上,在不到一分钟的时间内生成准确的10天天气预报,并支持多种应用场景,包括预测热带气旋路径、大气河流以及极端温度。
GraphCast 的输入为地球天气的最近两次状态(当前时间和6小时前),并预测6小时后的下一次天气状态。 单个天气状态用一个0.25°经纬度网格(721 × 1440)表示约相当于赤道上28×28公里的分辨率(Fig. 1a),每个网格点表示一组地表和大气变量(列于表1中)。与传统的数值天气预报(NWP)系统类似,GraphCast是自回归的:可以通过将其自身的预测作为输入进行“滚动”预测,从而生成任意长度的天气状态序列。
文中有描述,通过实验验证,用两个时间片的数据比一个性能好,而三个并没有带来足够的提升,必要性不足。但原因不明确,是因为通过网络传导,更之前是数据信息,已经充分包含在t-1/t-2两个时间片里面了?
GraphCast 的实现基于一种神经网络架构,采用图神经网络(GNN)的“编码-处理-解码”配置,总共包含3670万个参数。之前基于GNN的学习模拟器在学习由偏微分方程建模的流体和其他系统的复杂动力学方面非常有效,证明了它们适合建模天气动力学。因为 structure of GNN‘s representations and computations are analogous to learned finite element solvers。
编码器 (Fig. 1d) :使用单层GNN将正方形node上的5+6×37个变量(经过了零均值和单位方差归一化)映射为内部“multi-mesh”上的节点的属性。
multi-mesh (Fig. 1g) :是一个空间均匀的图,具有高空间分辨率。它通过对规则的二十面体(12个节点、20个面、30条边)进行六次迭代细分生成,每次细分将每个三角形划分为四个更小的三角形(导致面和边的数量增加四倍),并将节点重新投影到球面上。最终multi-mesh包含来自最高分辨率网格的40,962个节点(约为0.25°经纬度网格点数量的1/25),以及中间图中所有边的集合,形成了一个具有不同长度的边的平坦层级结构。每个层级上,点都具有5条边,对于第一层的12个节点,它具有6x5=30条边,第二层多出来的节点,具有5x5=25条边,以此类推
处理器 (Fig. 1e) :使用16层不共享的GNN层,在多网格上执行学习的消息传递,实现了通过较少的消息传递步骤高效传播局部和远程信息。
解码器 (Fig. 1f) :将处理器最后一层的学习特征从多网格表示映射回经纬度网格。它使用单层GNN,并预测输出作为对最近输入状态的残差更新(通过输出归一化实现目标残差的单位方差)。详细的架构信息见补充材料第3节。
在模型开发过程中,我们使用了来自ECMWF的ERA5重分析档案的39年历史数据(1979-2017)。训练目标是平均GraphCast预测状态在N个自回归步骤上的均方误差(MSE)与对应的ERA5状态之间的误差,并根据垂直层级加权。在训练过程中,N的值逐步从1增加到12(即从6小时到3天),通过时间反向传播计算损失的梯度(22)。GraphCast 使用梯度下降进行训练,总共耗时约四周,在32个Cloud TPU v4设备上进行批量并行。
3.模型细节
3.1 数据
记 $ X^t $ 为t时刻的特征数据集,$ X^t $ 中与特定网格点i(总共1,038,240个)对应的变量子集称为 $ x_{i}^t $ ,将227个目标变量中的每个变量j称为 $ x_{i,j}^t $ 。包含总计721 × 1440 × (5 + 6 × 37) = 235,680,480个值。需要注意的是,在极地,1440个经度点是相等的,因此实际的网格点数量略小。
GraphCast模型每个点上的变量值,一共是5项Surface variables、6项Atmospheric variables分别在37个Pressure levels上的值。5 + 6 × 37 = 227 variables per point in total。具体内容为:
-
地表变量(5项):2米温度 (2T)、10米U风分量 (10U)、10米V风分量 (10V)、海平面气压 (MSL)、总降水量 (TP)
-
大气变量(6项):温度 (T)、风的U分量 (U)、风的V分量 (V)、位势高度 (Z)、比湿 (Q)、垂直风速 (W)
-
压力水平(37项):1, 2, 3, 5, 7, 10, 20, 30, 50, 70, 100, 125, 150, 175, 200, 225, 250, 300, 350, 400, 450, 500, 550, 600, 650, 700, 750, 775, 800, 825, 850, 875, 900, 925, 950, 975, 1000.
GraphCast使用的坐标系统并没有特殊性,可以根据特定的应用需求进行更改。例如,使用均方根误差(RMSE)作为训练目标来优化风速向量在笛卡尔坐标系中的表现,会激励在预测不确定性下减小风速,这可能并非所期望的。使用极坐标在这种情况下可能更为合适。
3.2 Architecture overview
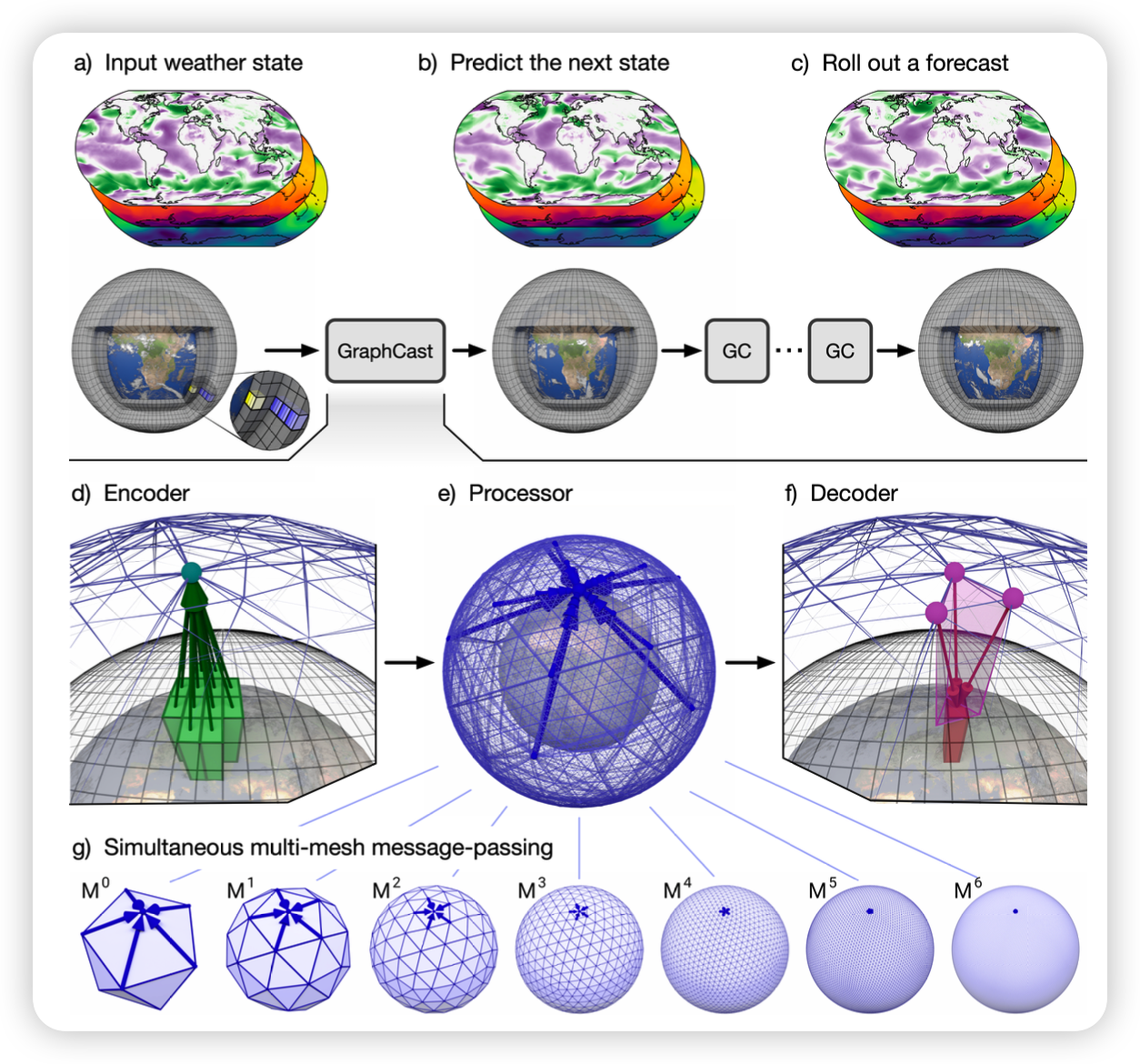
GraphCast是基于图神经网络(GNN)实现的,采用“编码-处理-解码”(encode-process-decode)配置(如图1d, e, f所示)。在该配置中,编码器将输入的纬度-经度网格上的地面和大气特征映射到一个multi-mesh上,处理器在该multi-mesh上执行多轮消息传递,解码器则将multi-mesh特征映射回输出的纬度-经度网格。
基于GNN的学习模拟器在学习流体和其他材料的复杂物理动态方面非常有效(18, 19),因为它们的表示和计算结构类似于学习的有限元求解器(20)。GNN的一个关键优势是,输入图的结构决定了表示的哪些部分通过学习的消息传递相互作用,从而能够在任意范围内进行空间交互。相比之下,卷积神经网络(CNN)仅限于计算局部区域内的交互(或者在膨胀卷积的情况下,计算规则步长的长范围交互)。虽然Transformers(43)也能进行任意长范围的计算,但由于计算所有交互时引发的二次内存复杂度,它们在处理非常大的输入时(例如GraphCast的全球输入,包含超过100万个网格点)无法良好扩展。现代的Transformers扩展通常通过稀疏化可能的交互来减少复杂度,这实际上使得它们类似于GNN(例如,图注意力网络(44))。
我们通过引入GraphCast的新内部multi-mesh表示,利用了GNN模型任意稀疏交互建模的能力。该multi-mesh表示允许在少数几轮消息传递中实现长范围交互,并且在全球范围内具有相对均匀的空间分辨率。对比之下,纬度-经度网格的空间是不均匀的,且在极地的分辨率非常高浪费计算资源。
我们的multi-mesh是通过首先将一个规则的二十面体(12个节点和20个面)迭代地分割6次来构建的,从而得到一个多层次的二十面体网格,在最高分辨率下共有40,962个节点和81,920个面。我们利用了粗网格节点是精细网格节点的子集这一事实,这使我们能够将来自网格层次结构各个层级的边叠加到最细的网格上。这个过程生成了一个多尺度的网格集,粗边桥接了多个尺度的长距离,而精细边则捕获了局部交互。图1g显示了每个单独的精细网格,图1e则显示了完整的多网格。
GraphCast的编码器(图1d)首先将输入数据从原始的纬度-经度网格映射到multi-mesh上的学习出的特征,使用一个具有定向边的GNN,从网格点到multi-mesh进行映射。然后,处理器(图1e)使用一个16层深的GNN在多网格上执行学习的消息传递,通过长距离边缘实现空间信息的高效传播。解码器(图1f)则使用一个定向边的GNN将最终的多网格表示映射回纬度-经度网格。
编码器和解码器不要求原始数据按照规则的直角网格排列,也可以应用于任意网格状的状态离散化(20)。该架构通常基于许多成功应用于复杂流体系统和其他物理领域的GNN学习模拟器(18, 19, 45)。类似的方法也被用于天气预报(13),并取得了令人鼓舞的结果。
在单个Cloud TPU v4设备上,GraphCast可以在不到60秒的时间内生成一个0.25°分辨率、10天(每6小时一步)的预报。作为对比,ECMWF的IFS系统在一个11,664核心的集群上运行,生成一个0.1°分辨率、10天的预报(前90小时以1小时步长发布,93至144小时以3小时步长发布,150至240小时以6小时步长发布,计算时间约为1小时(8))。
3.3 图结构
Grid nodes
网格节点代表纬度-经度点,除前面提到的t-1、t时刻的(5 + 6 × 37)个变量值,还包括t-1、t、t+1三个时刻的一些静态变量,比如大气顶层的总太阳辐射(以小时累计),本地时间的正弦和余弦(标准化到[0, 1)区间),以及一年进度的正弦和余弦(标准化到[0, 1)区间);还有一些与时间无关的常数项,包括二进制的陆海掩码、地表的重力势、纬度的正弦值、经度的正弦和余弦值。
在0.25°分辨率下,总共有721 × 1440 = 1,038,240个网格节点,每个网格节点具有474个输入特征(包括5个地表变量 + 6个大气变量 × 37层 × 2步 + 5个强迫项 × 3步 + 5个常数项)。
Mesh nodes
Mesh nodes有3个features,纬度的余弦值、经度的正弦和余弦值。
Mesh edges
NumEdges在0、1、2、3、4、5、6这7个level的个数分别为:60 240 960 3,840 15,360 61,440 245,760。最终总边数为 327,660, each with 4 input features.
Grid2Mesh edges
是单向边,connect sender grid nodes to receiver mesh nodes. 如果grid node与mesh node之间的距离小于或等于Mesh edge中最短的边的长度的0.6倍,则添加一条边,确保每个grid node至少连接到一个mesh node。
This results on a total of 1,618,746 Grid2Mesh edges, each with 4 input features.
Mesh2Grid edges
unidirectional edges that connect sender mesh nodes to receiver grid nodes.
对于每一个经纬度的grid node,都能唯一落到某一个最细粒度的三角形平面上,这个三角形平面有三个顶点,从这三个Mesh node连三根线到grid node,就构成了三条Mesh2Grid边。
This results on a total of 3,114,720 Mesh2Grid edges (3 mesh nodes connected to each of the 721 × 1440 latitude-longitude grid points), each with 4 input features.
3.4 Encoder/Processor/Decoder
Encoder首先通过五个多层感知机(MLP)将3.3中5种点/边的特征embed到latent space中。然后,用interaction network,就是MLP,把grid node信息传递到它的出边Grid2Mesh,再传递给mesh node。
Processor只处理mesh nodes和mesh edges,单层是一个标准的交互网络(Interaction Network)(17, 46),它首先使用相邻节点的信息更新每个网格边;然后,它通过聚合所有到达该网格节点的边的信息来更新每个网格节点;更新完这两个元素后,表示将通过残差连接更新,并且为了简化符号,也会将变量重新分配。一共有16层。
Decoder与Encoder类似,两次消息传递,把mesh node的信息传回给grid node。
最后Output层是个MLP,把grid node上的信息映射成输出。
GraphCast 中的神经网络全部是 MLP,每个 MLP 都有一个隐藏层,隐藏层和输出层的大小为512(除了解码器的最终层,其输出大小为227,匹配每个网格节点的预测变量数)。在 GNN 中使用单层隐藏层的 MLP 是一种常见做法,因为常规经验和我们自己的实验表明,增加消息传递的层数并减少 MLP 的深度效果最好。初步实验表明,MLP 深度的变化支持这一选择
3.5 Training objective
就是MSE

GenhCast
1.简介
是在GraphCast基础上,2024年5月发表的新进展。
传统的天气预报基于数值天气预报(NWP)算法,这些算法大致解算了大气动力学的方程。确定性NWP方法将当前的天气估算映射到一个未来天气将如何展开的预报上。这个单一的预报只是其中的一种可能性,因此,为了建模不同未来天气情景的概率分布(Kalnay,2003;Palmer和Hagedorn,2006),气象机构越来越依赖于“集成预报”,生成多个基于NWP的预报,每个预报模拟一个单一的可能情景(ECMWF,2019;Palmer,2019;Roberts等,2023;Yamaguchi等,2018;Zhu等,2012b)。欧洲中期天气预报中心(ECMWF)的ENS(ECMWF,2019)是ECMWF广泛集成预报系统(IFS)中的最先进的基于NWP的集成预报,将取代其确定性预报HRES(ECMWF,2024)。虽然ENS和其他基于NWP的集成预报在建模天气分布方面非常有效,但它们仍然容易出错,运行速度较慢,并且需要大量工程工作。
近年来,基于机器学习(ML)的天气预报(MLWP)方法提供了NWP方法的替代方案,并已证明在非概率性预报方面提供了更高的准确性和效率(Bi等,2023;Chen等,2023;Keisler,2022;Kurth等,2022;Lam等,2023;Li等,2023;Nguyen等,2023)。这些方法通常侧重于预测可能轨迹的平均值,而相对较少强调量化预报的不确定性。它们通常训练以最小化均方误差(MSE),因此在较长的提前时间内,往往会产生模糊的预报状态,而不是可能的特定天气状态的实现(Lam等,2023)。也有一些有限的尝试,试图使用传统的初始条件扰动方法来生成基于MLWP的集成预报(Bi等,2023;Kurth等,2022;Li等,2023),但它们没有解决模糊问题,也未能与像ENS这样的操作集成预报相媲美。一个例外是Neural GCM(Kochkov等,2023),这是一种混合NWP-MLWP方法,结合了传统NWP的动力学核心和局部基于ML的参数化,显示出与操作集成预报竞争的表现。然而,它的集成预报分辨率为1.4°,比操作NWP预报的分辨率低一个数量级,并且在扩展到操作环境时面临严重的挑战。
2. GenCast
在这里,我们介绍了一种概率性天气模型——GenCast——它生成0.25°分辨率的全球15天集成预报,首次比世界顶级的操作集成系统——ECMWF的ENS更准确。生成一个单一的15天GenCast预报大约需要8分钟,且多个预报可以并行生成。
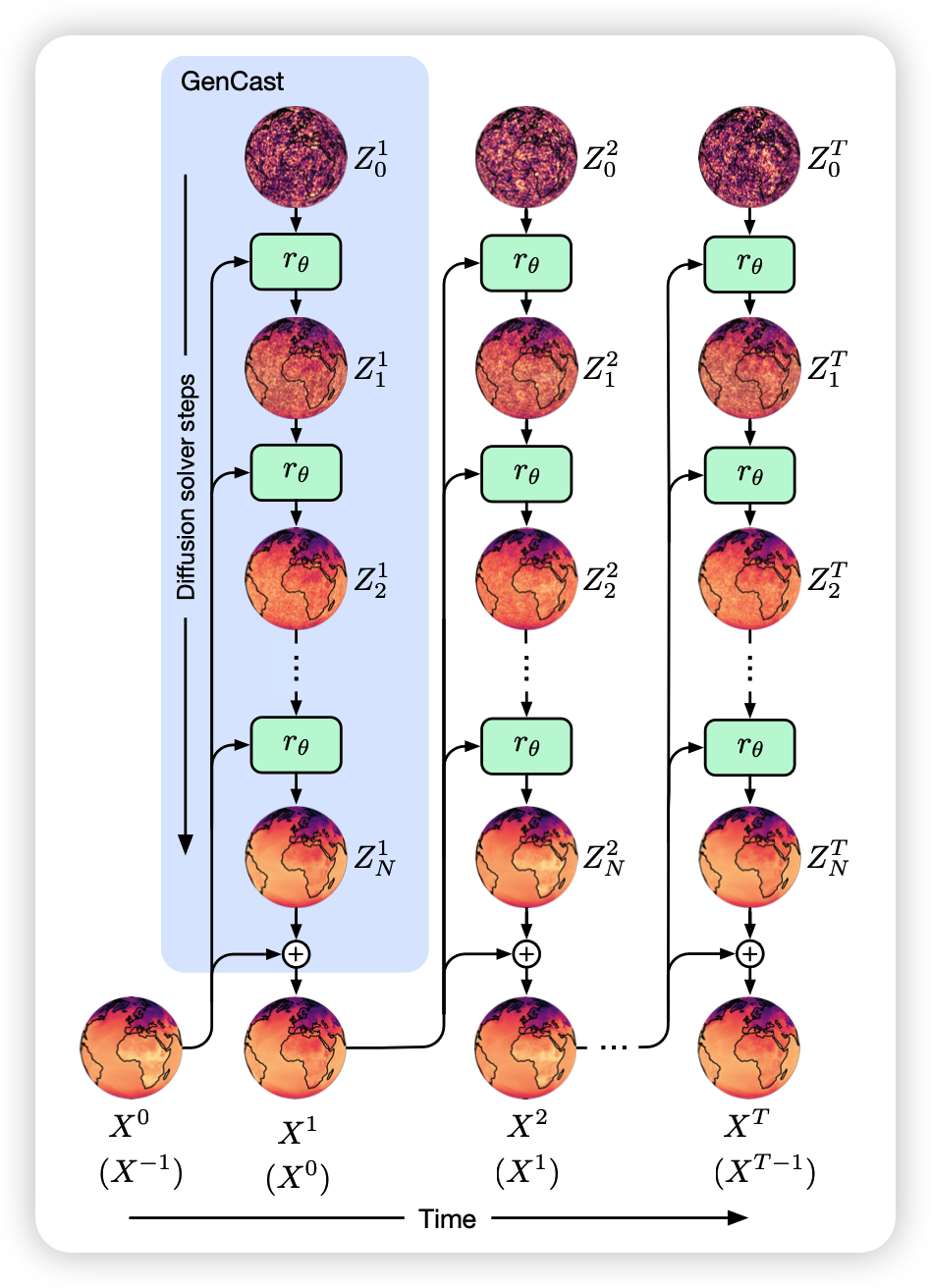
GenCast建模了未来天气状态 𝑋𝑡+1 的条件概率分布 𝑝(𝑋𝑡+1∣𝑋𝑡,𝑋𝑡−1),即在当前和前一天气状态的条件下预测未来天气状态。一个长度为 𝑇 的预报轨迹 通过对初始和前一状态的条件建模,并对后续状态的联合分布进行因子分解来建模,每一步都是自回归采样的。
GenCast实现为条件扩散模型conditional diffusion model(Karras等,2022;Sohl-Dickstein等,2015;Song等,2021),这是一种生成型机器学习模型,用于从给定的数据分布中生成新样本,支撑了近年来在自然图像、声音和视频建模方面的许多进展,统称为“生成性AI”(Croitoru等,2023;Yang等,2023)。扩散模型通过迭代细化过程工作。未来的大气状态 𝑋𝑡+1 是通过迭代细化一个完全从噪声初始化的候选状态 𝑍𝑡+1 来产生的,并且它受前两个大气状态 𝑋𝑡,𝑋𝑡−1 的条件限制。图1中的蓝色框显示了如何从初始条件生成第一步预报,以及如何自回归地生成完整轨迹。由于每个时间步的预报都是以噪声(即 𝑍𝑡+1)初始化的,因此可以通过不同的噪声样本重复此过程,从而生成一组轨迹。有关详细信息,请参见D.1部分。
在每个迭代细化阶段,GenCast应用了一个由编码器、处理器和解码器组成的神经网络架构。编码器组件将输入 𝑍𝑡+1 以及条件 𝑋𝑡,𝑋𝑡−1 从本地经纬度网格映射到一个在6次细化的二十面体网格上的内部学习表示。处理器组件是一个graph transformer(Vaswani等,2017),其中每个节点都关注其k-hop邻域。解码器组件将内部网格表示映射回经纬度网格上。
GenCast的训练使用了40年ERA5重分析数据(Hersbach等,2020),涵盖1979年至2018年,使用标准的扩散模型去噪目标(Karras等,2022)。至关重要的是,虽然我们只在单步预测任务上直接训练GenCast,但它可以自回归地展开生成15天的集成预报。D部分提供了GenCast架构和训练协议的完整细节。
在评估GenCast时,我们使用ERA5重分析数据初始化它,并结合来自ERA5数据同化集成(EDA)的扰动(Isaksen等,2010),这些扰动反映了初始条件的不确定性。更多细节见C部分。
3. 一些模型细节
| 扩散模型的核心是噪声的加入与去除,噪声来自于某个分布 𝑝𝑛𝑜𝑖𝑠𝑒(· | 𝜎),其中 𝜎 是噪声级别。在使用扩散生成自然图像时(Ho 等,2020),通常选择 i.i.d. 高斯分布作为噪声分布,扩散模型的早期理论大多是基于高斯白噪声的情况开发的。在球面上进行白噪声过程时,它是各向同性的或旋转不变的,其特征是其球面调和谱在期望上是平坦的。然而,如果我们尝试通过在等纬度-经度网格的格点上采样 i.i.d. 噪声来在有限分辨率下近似它,那么这些性质将不再成立。这是因为接近极点的格点密度更大,导致球面调和域中的高频分量增多。 |
在实证上,我们发现这并不是一个致命的问题;然而,我们发现通过采用一种对球面几何敏感的噪声采样方法,能够获得一些小但一致的改进。我们在球面调和域中采样各向同性的高斯噪声,其期望的功率谱在我们的网格能够分辨的波数范围内是平坦的,之后被截断。然后,我们使用逆球面调和变换(Driscoll 和 Healy,1994)将其投影到离散网格上。得到的每个网格单元的噪声值并非独立,尤其是接近极点时,但在赤道处的分辨率下,它们近似独立,且显示出各向同性和平坦的功率谱。
参考文献
一个team member的分享 https://www.youtube.com/watch?v=PD1v5PCJs_o GraphCast GenCast