1.1. Abstract
端到端链路追踪,包括broswer、apps、backend服务。
near real-time:实时上报,可以实时查询+分析性能数据,每天 十亿 条trace
三大挑战:
- 能支持Facebook各技术栈中的各种不同组件,他们有不同的执行模型、性能模型;
- 支持ad-hoc性能分析;
- 支持用户深度定制,从trace采样 到特征提取&展示
1.2. Introduction
每个用户操作,如loading a page on Facebook.com,都需要贯穿客户端、网络、后端服务的复杂操作。
一些偶然因素也会影响性能,比如部署代码、修改配置、分用户测试(AB分流)、数据中心硬件设施特性不同 等等。
Canopy是个普适的 performance traces 性能追踪框架,在X-Trace Dapper之上加以扩展。核心是全系统传递每次请求的identifier,根据identifier进行数据关联。有三大挑战:
- 第一,数据建模问题。端到端各类数据差别巨大,有诸多行为模型、各种变量。直接应用结构化数据笨重且不可能实现,总不能让所有rd都理解 从底层event data 到顶层结构化数据 之间的映射 (就像让业务理解什么时候该把什么数据转换成mtrace span)。而且这个模型得考虑如果兼容遗留组件、怎么在未来支持新组件。and,更改总是困难的(想想我们的版本收敛)
- 第二,顶层聚合&分析链路的需求 并不能直接通过底层丰富的原始数据直接支撑。需要有工具来基于原始数据做slice, group, filter, aggregate, and summarize traces
- 第三,所有rd都需要使用这个追踪组件,它需要支撑 1 一个普适入口,来支持偶尔的查询需求,已经更上层的分析场景;2 深度定制,从trace采样,到feature收集、到数据分析。
Canopy搞了个pipline。rd或中间件通过canopy api将上报性能数据,canopy把这些数据映射成一种灵活的事件表示(数据结构是?)。pipline实时接收这些事件;把事件重新组织成一个更高层的追踪模型,以方便查询及分析;从追踪模型中提取用户自定义特征数据;把结果集输出 用于定制化的聚合展示。
Canopy运行了2年,13亿条trace,129 performance datasets ranging from high-level end-to-end metrics to specific customized use cases (少了点啊)。
主要贡献下面三点:
一种解耦设计:将追踪行为(应该是说埋点方式?)与追踪模型解耦,两者可以分别演进
- dapper zapkin htrace这些组件都是在埋点时就直接生成好了trace的表示结构(span),有这么几个问题:1 有一些行为模型很难表示成span trees,比如queues、异步调用、聚合处理(multiple-parent causality)。
一个完整pipline,将trace转化成基于用户特征的数据集,便于快速分析
- RD应该能够基于所有traces、针对任意特征值,去做matrics数据的展示、过滤、聚合。这个不太好做:一条trace数据就可能包含成千上万的性能时间,一次查询又可能涉及到巨量trace,目前Canopy只允许查询一个时间段内的数据,不会大量回溯历史数据;除非我们提供抽象,否则用户不得不直接消费trace数据,提取high-level feature将需要复杂的运算。
一组可定制化的追踪组件,对同一份数据可提供不同展示view
1.3. Motivation
曾经facebook内部有很多个追踪组件,都有特定用途且难于扩展,比如前段的、rpc的、app的。【TODO,MTrace是不是能打通其他 端trace组件?做个模型转换 或 先简单做个id关联】
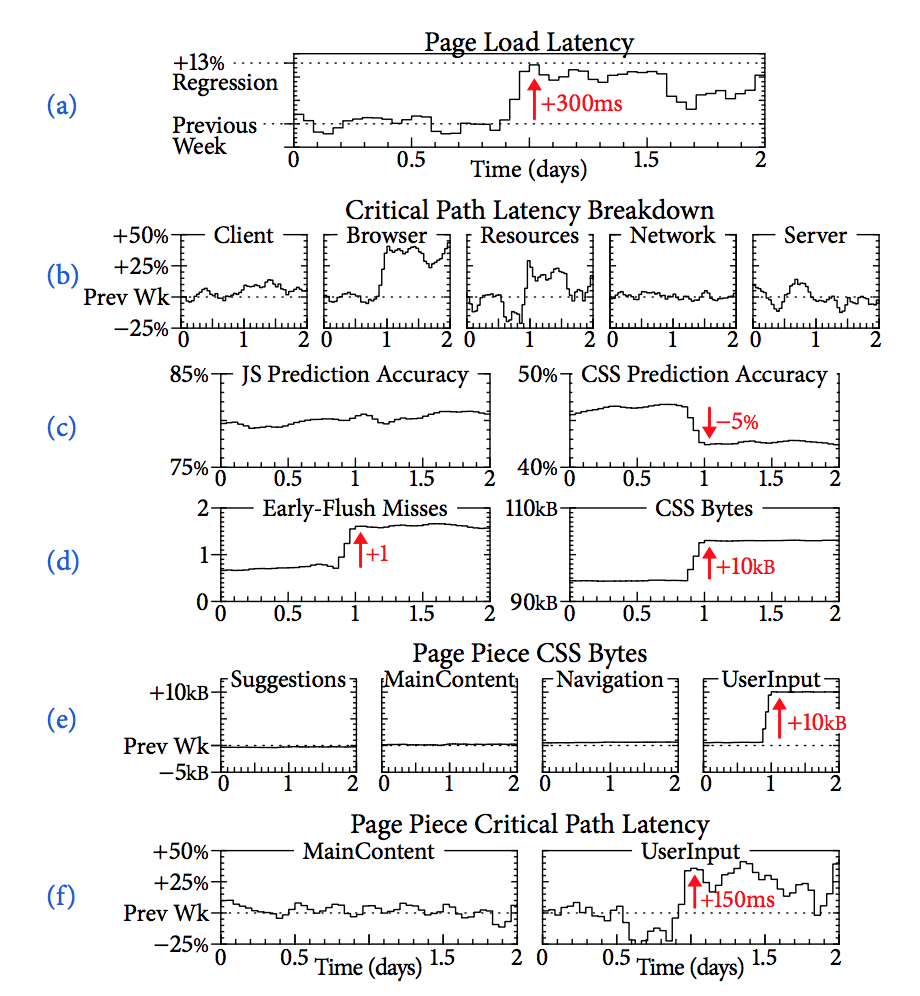
在例子中,Canopy看到最近一段时间,加载图片的TP数据极具上涨到了300ms (TP同比也是异常链路分析的来源)
而后对整个链路环节分段分析,找到哪几个服务的环比有了变更(我们现在只有TP环比对比,但没有和异常链路结合在一起)
最终问题原因是early flush未命中,导致web多了一次远程请求(像这种问题,如果不是end-to-end,只看后端的单条链路,是看不出来的 )
The page load regression corresponded to a 5% drop in CSS prediction accuracy and an additional 10kB of CSS before the page could display (1d); this unnecessary CSS took the place of useful resources, forcing clients to wait for the next batch of resources before the page could display (an early flush miss).
1.4. Design
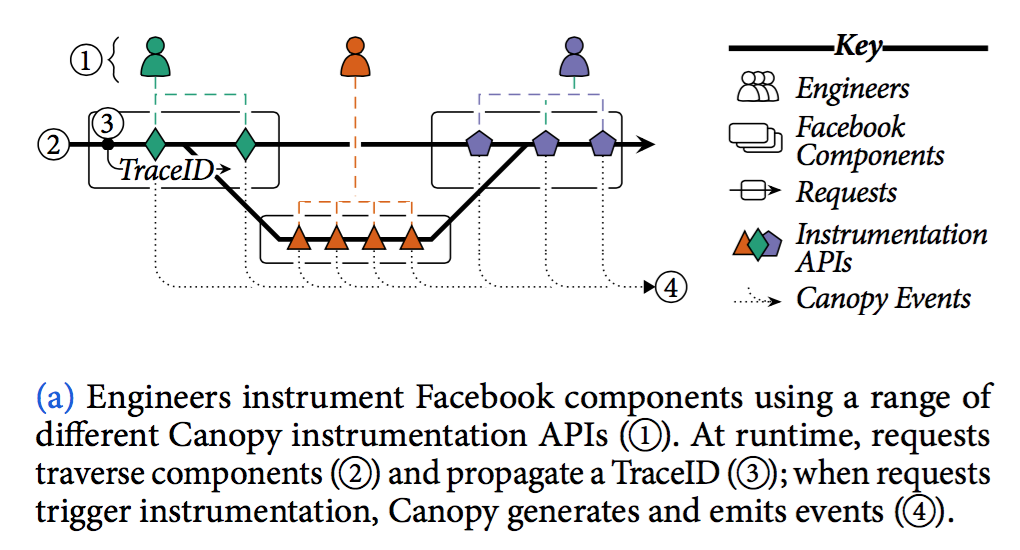
①为啥API要不一样?e.g. counters, logs, causal dependencies。接口类型上看确实比trace api好理解,但这就是所谓的“允许各个组件独立演进”么?
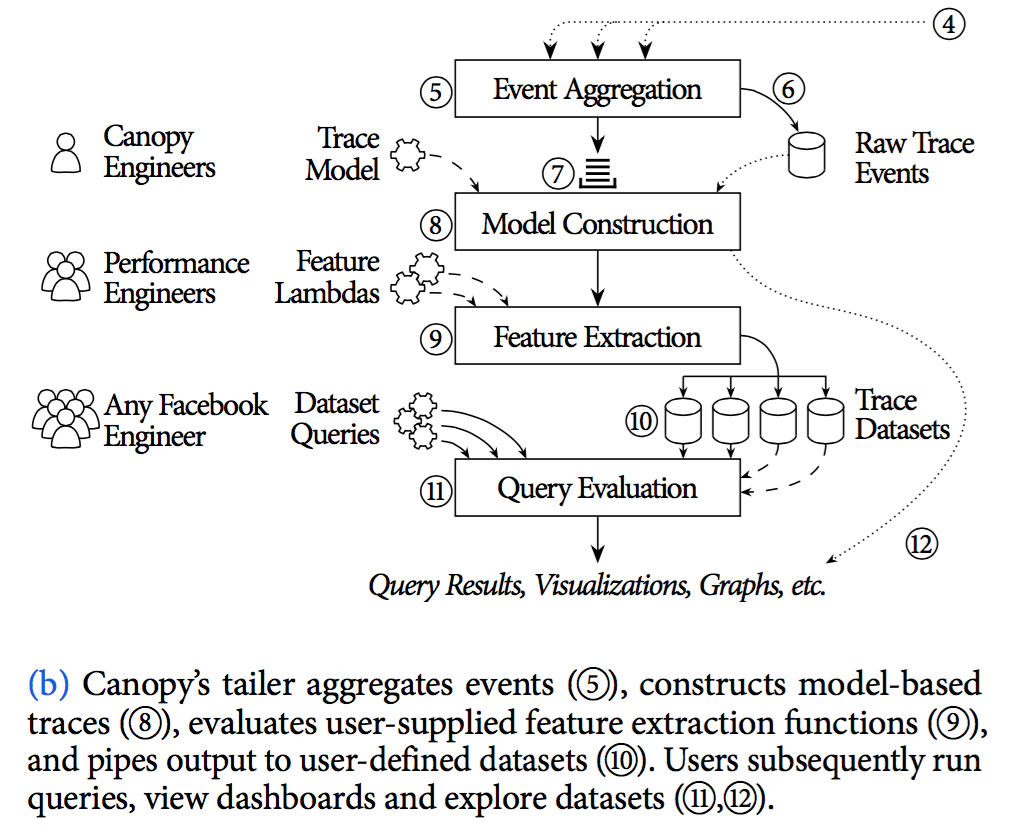
⑤⑥Canopy’s tailer 聚集这些events,且会存储原生trace events (估计是临时缓存,不是持久化存储)
⑦当tailer判断一条trace的所有event都已经接收到了,这些events会被遗弃塞进queue里,等待下一步处理
⑧生成结构化的trace数据,将这一堆event映射到trace model
⑨执行用户提交的特征提取方程,feature lambdas,
⑩pipes将数据输出到用户指定存储。(是不是解决了存储空间浪费问题??只有用户关心的trace被留了下来,其余trace都过滤丢掉了。 做好难度还是挺大的,处理速度慢实时性就会差;让这么多RD整明白也需要很好的产品设计)
而后用户执行查询、view展示、数据分析。
所以数据提取方程是基于同一份结构化数据来跑的,只读不写可并行。 有点像kafka多consumer消费。会不会出现互相影响?比如有个特征提取方程计算特别慢?如果过了time scales就不管了呗?
requests fan out and in traceid都会传下去,也就是说trace不是树形?
所有数据会封装成结构松散的events

tailer是分布式的,根据traceId做分片处理event
会有一份数据pipe到Scuba,一个适用于性能数据存储的内存数据库
1.4.1. Instrumentation APIs
There are several reasons decoupling instrumentation APIs is a successful approach.
对于一个特定场景,rd只会使用到几个固定api,减少理解成本
封装好的少量api屏蔽了底层实现细节,埋点更鲁棒
api不绑定顶层trace模型,所以兼容性好。向上更容易对接新组件,向下也可以去集成第三方追踪组件,比如htrace或Cassandra tracing
1.4.2. Trace Events
收集到的埋点数据会表示成events,events可组成一个DAG:directed, acyclic graph 有向无环图,所以不一定是树。所以这确实是个minimal assumptions about execution models,能囊括mq这种模型
在同一个处理线程中,使用序列号和时间戳 来排序events;如果发生远程交互,会传递client event的id,这个event也会在client和server两端都记录,通过这个id来关联
1.4.3. Modeled Traces
会把events处理表示成更高层的trace model,屏蔽掉不同组件、不同版本的event差异。
model有四部分:execution units, blocks, points, and edges
- execution units:执行单元,可近似理解为一个线程所做的所有操作 (如果是组件内的跨线程,应该也会合并到一个execution units,应该对标我们的span)
- blocks:一个执行单元里的计算片段,感觉可对标内部方法
- points:瞬时事件:
- edges:非必须,表示points之间的关系 (那直接用blocks不就行了么??)
这四种类型并不是收集event的时候就指定的,而是会维护一个event到类型之间的映射。比如 有明确开始和结束事件的计算片段 会被映射成block;一次队列操作会映射 enqueue、dequeue、完成操作 三种event
edges不止可以描述调用关系,也可以用来表示像mq这种关联关系。
每个event都可以关联性能数据,比如messages, labels, stack traces, sets of values, and counters
1.4.4. Trace Datasets
Row
dataset的一行可以是一条trace中的特征元素,比如 这条trace的全请求耗时、国家、浏览器型号;也可以是(TraceID, PagePieceID)对应的一些元素
Feature
每列都是个feature,可以是个简单提取出来的lable,也能是个聚合计算出来的值,甚至能算两个points间固定path上的聚合指标。列可以是numerics, strings, stacktraces, sets, and lists等
Extraction
从trace中提取feature 是 提取方程(feature extraction functions)的行为:f: Trace -> Collection<Row
要求:
- RD能快速迭代、部署特征提取方程
- 可扩展,能不断支持新分析
- 鼓励模块化,以及应用其他方程的提取结果来
Analysis
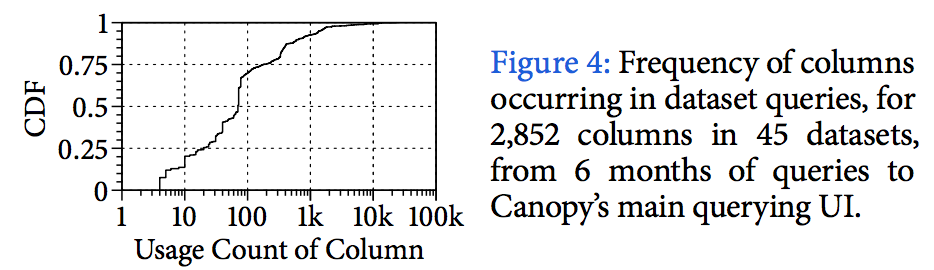
plots the usage frequency for 2,852 columns from 45 datasets, aggregated over 6 months of queries to Canopy’s main dataset-querying UI. The most popular column is page load latency from the main Canopy dataset, used by 23,224 queries. However, most columns contributed to fewer than 100 queries, with a median of 70
1.5. Implementation
1.5.1. Client
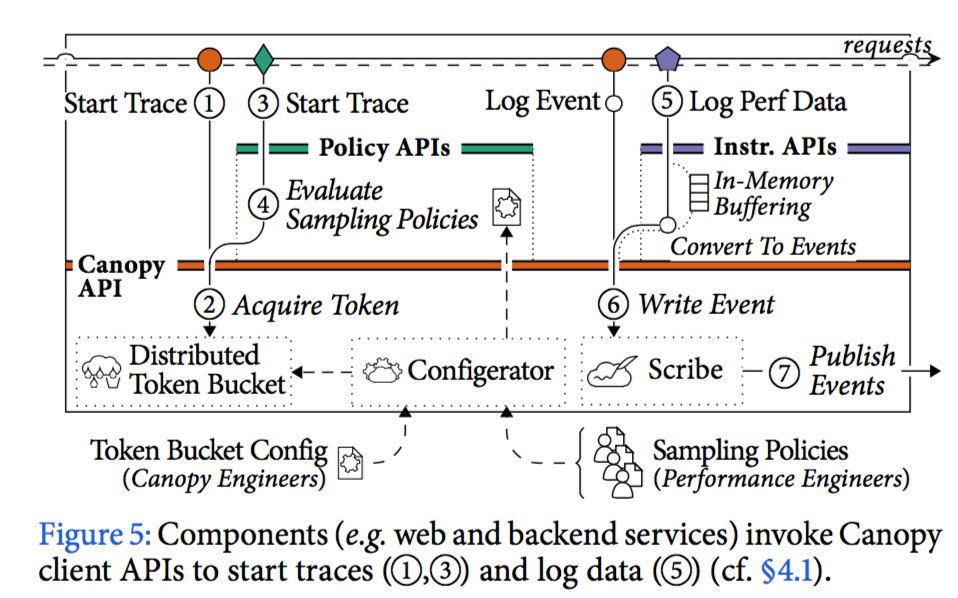
在第二步,颁发token(traceid)是有频率限制的,默认5个每秒,拿到token的请求才会生成trace。
也有低频api采集不到等问题,也支持自定义采样策略,但除了概率、qps等策略外,还支持按feature来匹配采样策略(比如哪个user的所有请求都上报)